4 Fluxo de trabalho: estilo de código
As boas práticas de formatação em programação são como as regras gramaticais: você pode até viver sem elas, mas elas certamente tornam asCoIsaSmaisfáCeiSdeler. Mesmo sendo iniciante em programação, é uma boa ideia observar e implementar as boas práticas na escrita do seu código. Usar um estilo de escrita consistente torna mais fácil para outras pessoas (incluindo você no futuro!) ler o seu trabalho, e é particularmente importante se você precisar pedir ajuda para outra pessoa. Este capítulo apresentará os pontos mais importantes do guia de estilo tidyverse, que é usado em todos os capítulos deste livro.
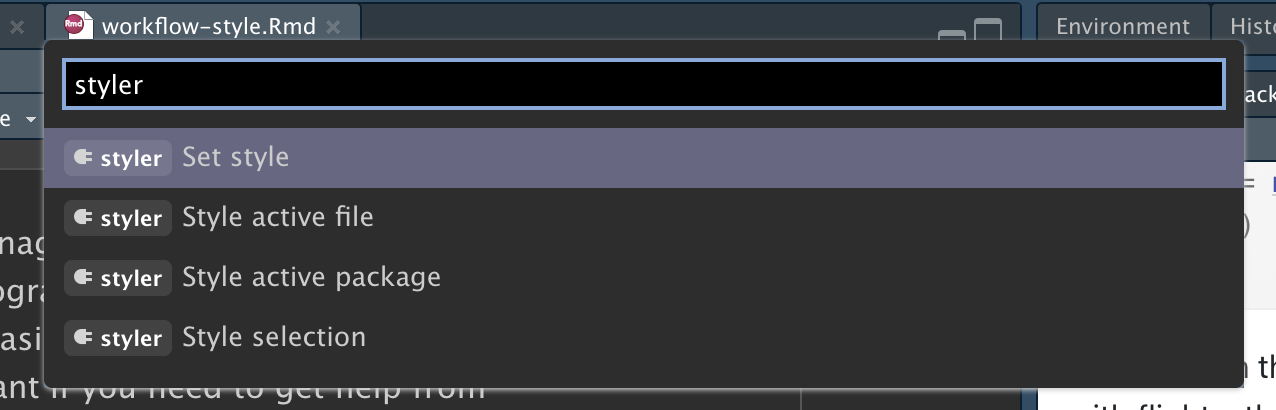
Formatar seu código de acordo com as convenções de estilo pode parecer um pouco chato no início, mas se você praticar, isso vai se tornar natural rapidamente. Além disso, existem algumas ótimas ferramentas para formatar de forma rápida códigos antigos, como o pacote styler de Lorenz Walthert. Depois de instalar o pacote com o comando install.packages("styler"), uma maneira fácil de usá-lo é por meio da paleta de comando (command palette) do RStudio. A paleta de comando permite que você use qualquer comando interno do RStudio e muitas extensões (addins) fornecidas por pacotes. Abra a paleta pressionando Cmd/Ctrl + Shift + P, em seguida, digite “styler” para ver todos os atalhos oferecidos pelo styler. A Figura 4.1 mostra os resultados.
Neste capítulo, usaremos os pacotes tidyverse e dados para os exemplos com código.
4.1 Nomes
Falamos um pouco sobre nomes em Seção 2.3. Lembre-se de que os nomes de variáveis (aqueles criados por <- e aqueles criados por mutate()) devem usar apenas letras minúsculas, números e _. Use _ para separar palavras dentro de um nome.
Como regra geral, é melhor usar nomes longos, descritivos e que sejam fáceis de entender, do que nomes curtos só pela rapidez para digitar. Os nomes curtos economizam relativamente pouco tempo ao escrever o código (especialmente porque o recurso de autocompletar (autocomplete) ajuda a terminar de digitá-los), mas isso pode te atrasar depois, quando voltar ao código antigo e precisar decifrar uma abreviação bem difícil de entender.
Se você tem um monte de nomes para coisas que estão relacionadas entre si, faça o possível para ser consistente. É fácil surgirem inconsistências quando você esquece uma convenção anterior, então não se sinta mal se você tiver que voltar e renomear as coisas. Em geral se você tem um monte de variáveis que são uma variação de um tema específico, é melhor dar a elas um prefixo comum em vez de um sufixo comum, porque o recurso de autocompletar funciona melhor no início de uma variável.
4.2 Espaços
Use espaços em ambos os lados dos operadores matemáticos, exceto ^ (operadores: +, -, ==, <, …), e em torno do operador de atribuição (<-).
# Tente escrever assim:
z <- (a + b)^2 / d
# Evite escrever assim:
z<-( a + b ) ^ 2/dNão coloque espaços dentro ou fora de parênteses para chamadas de funções normais. Sempre coloque um espaço depois de uma vírgula, assim como escrevemos em português.
Tudo bem adicionar espaços extras se isso melhorar o alinhamento. Por exemplo, se você estiver criando várias variáveis com um mutate(), você pode querer adicionar espaços para que todos os sinais de = fiquem alinhados.1 Isso facilita a leitura do código.
4.3 Pipes (Encadeamento)
O |> (chamado de pipe) deve sempre ter um espaço antes dele e deve ser sempre a última coisa em uma linha. Isso torna mais fácil adicionar novas etapas, reorganizar etapas existentes, modificar elementos dentro de uma etapa e obter uma visão geral do código ao passar os olhos sobre os verbos no lado esquerdo.
Se a função para a qual você está encadeando tem argumentos nomeados (como mutate() ou summarize()), coloque cada argumento em uma nova linha. Se a função não tiver argumentos nomeados (como select() ou filter()), mantenha tudo em uma linha, caso caiba. Caso não caiba, você deve colocar cada argumento em sua própria linha.
Depois da primeira etapa do encadeamento, recue cada linha (indente) em dois espaços. O RStudio colocará automaticamente os espaços para você após a quebra de linha feita logo depois do pipe |>. Se você estiver colocando cada argumento em sua própria linha, recue em mais dois espaços. Certifique-se de que o ) (fechamento de parêntesis) esteja em sua própria linha e não recuada para corresponder à posição horizontal do nome da função.
# Tente escrever assim:
voos |>
group_by(cauda) |>
summarize(
atraso = mean(atraso_chegada, na.rm = TRUE),
n = n()
)
# Evite escrever assim:
voos|>
group_by(cauda) |>
summarize(
atraso = mean(atraso_chegada, na.rm = TRUE),
n = n()
)
# Evite escrever assim:
voos|>
group_by(cauda) |>
summarize(
atraso = mean(atraso_chegada, na.rm = TRUE),
n = n()
)Tudo bem ignorar algumas dessas regras se as etapas de seu encadeamento (pipeline) se encaixar facilmente em uma linha. Mas, em nossa experiência coletiva, é comum que pequenos trechos de código cresçam, então você vai acabar economizando tempo no longo prazo começando com todo o espaço vertical de que precisa.
Por último, tenha cuidado ao escrever pipelines muito longos, com mais de 10-15 linhas, por exemplo. Tente dividir o pipeline em subtarefas menores, dando a cada tarefa um nome que informe o objetivo daquela etapa. Os nomes ajudarão quem está lendo a entender o que está acontecendo e torna mais fácil de verificar se os resultados intermediários estão como o esperado. Dê nomes informativos sempre que puder. Por exemplo, quando você alterar a estrutura dos dados em seu nível básico, como após pivotar ou sumarizar. Não espere acertar na primeira tentativa! Isso significa que você tem que dividir os encadeamentos longos se houver estados intermediários que possam receber bons nomes.
4.4 ggplot2
As mesmas regras básicas que se aplicam ao pipe também se aplicam ao ggplot2; você deve tratar o + da mesma forma que o |>.
Lembre-se, se você não puder colocar todos os argumentos de uma função em uma única linha, coloque cada argumento em sua própria linha:
voos |>
group_by(destino) |>
summarize(
distancia = mean(distancia),
velocidade = mean(distancia / tempo_voo, na.rm = TRUE)
) |>
ggplot(aes(x = distancia, y = velocidade)) +
geom_smooth(
method = "loess",
span = 0.5,
se = FALSE,
color = "white",
linewidth = 4
) +
geom_point()Preste atenção quando mudar do |> para o + no encademanto do código. Gostaríamos que essa transição não fosse necessária, mas infelizmente, o ggplot2 foi escrito antes do pipe ser descoberto.
4.5 Comentários de seção
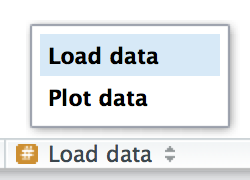
Conforme seus scripts ficam mais longos, você pode usar comentários de seção para dividir seu arquivo em partes gerenciáveis:
# Carregar os dados --------------------------------------
# Plotar os dados --------------------------------------O RStudio fornece um atalho de teclado para criar esses cabeçalhos (Cmd/Ctrl + Shift + R), e os exibe no menu de navegação de código na parte inferior esquerda do editor, como mostrado na Figura 4.2.
4.6 Exercícios
- Aplique as boas normas de formatação aos seguintes pipelines seguindo as diretrizes apresentadas neste capítulo.
voos|>filter(destino=="IAH")|>group_by(ano,mes,dia)|>summarize(n=n(),
atraso=mean(atraso_chegada,na.rm=TRUE))|>filter(n>10)
voos|>filter(companhia_aerea=="UA",destino%in%c("IAH","HOU"),saida_programada>
0900,chegada_prevista<2000)|>group_by(voo)|>summarize(atraso=mean(
atraso_chegada,na.rm=TRUE),cancelado=sum(is.na(atraso_chegada)),n=n())|>filter(n>10)4.7 Sumário
Neste capítulo, você aprendeu os princípios mais importantes da convenção de estilo de código. Essa convenção pode parecer um conjunto de regras arbitrárias (porque são!), mas com o tempo, à medida que você escreve mais código e compartilha código com mais pessoas, você verá como é importante ter um código fácil de ser lido e entendido. E não se esqueça do pacote styler: é uma ótima maneira de melhorar de forma rápida a qualidade do código mal formatado.
No próximo capítulo, voltamos às ferramentas de ciência de dados, aprendendo sobre tidy data (dados organizados). Tidy data é uma maneira consistente (convenção) de organizar seus conjuntos de dados que é usada em todo o tidyverse. Essa consistência torna sua vida mais fácil porque, uma vez que você tem dados organizados de acordo com os conceitos de tidy data, eles irão funcionar com a grande maioria das funções do tidyverse. Claro, a vida nunca é fácil, e a maioria dos conjuntos de dados que você encontrará na vida real não serão tidy. Por esse motivo, também ensinaremos como usar o pacote tidyr para organizar seus dados desorganizados.
Como
horario_saidaestá no formatoHMMouHHMM, fazemos uma divisão do número inteiro (%/%) para obter a hora e o resto (também conhecido como módulo,%%) para obter o minuto.↩︎