20 Planilhas
20.1 Introdução
No Capítulo 7 você aprendeu sobre importação de dados de arquivos de texto como .csv e .tsv. Agora chegou a hora de aprender a extrair dados de planilhas, tanto do Excel quanto do Planilhas Google (Google Sheets). Para isto, usaremos muito do que você aprendeu no Capítulo 7, mas discutiremos também considerações adicionais e complexidades presentes quando trabalhamos com dados vindos de planilhas.
Se você ou seus colaboradores estão usando planilhas para organizar dados, nós recomendamos fortemente a leitura do artigo “Organização de Dados em Planilhas (Data Organization in Spreadsheets) de Karl Broman e Kara Woo: https://doi.org/10.1080/00031305.2017.1375989. As boas práticas presentes neste artigo evitarão dores de cabeça ao importar dados de planilhas para análise e visualização com o R.
20.2 Excel
O Microsoft Excel é um software muito utilizado onde os dados são organizados em planilhas (worksheets) dentro de arquivos Excel (spreadsheet).
20.2.1 Pré-requisitos
Nesta seção, você aprenderá como carregar dados de arquivos do Excel para o R com o pacote readxl. Este pacote faz parte dos componentes secundários (non-core) do tidyverse, portanto devemos carregá-lo explicitamente, apesar dele já ser instalado automaticamente quando você instala o tidyverse. Posteriormente, usaremos também o pacote writexl, que nos permite criar planilhas do Excel.
20.2.2 Iniciando
Muitas funções do readxl te permitem importar arquivos do Excel para o R:
-
read_xls()importa arquivos Excel que estejam no formatoxls. -
read_xlsx()importa arquivos Excel que estejam no formatoxlsx. -
read_excel()pode importar arquivos em ambos os formatosxlsexlsx. Ela identifica o formato baseado no tipo de arquivo de entrada.
Estas funções possuem uma sintaxe similar às outras funções introduzidas anteriormente para importar outros tipos de arquivos, por exemplo: read_csv(), read_table(), etc. No restante deste capítulo focaremos no uso da função read_excel().
20.2.3 Importando arquivos do Excel
A Figura 20.1 mostra como é a planilha do Excel que iremos importar para o R. Esta planilha pode ser baixada em https://github.com/cienciadedatos/pt-r4ds/raw/traducao-pt-2ed/data/estudantes.xlsx.
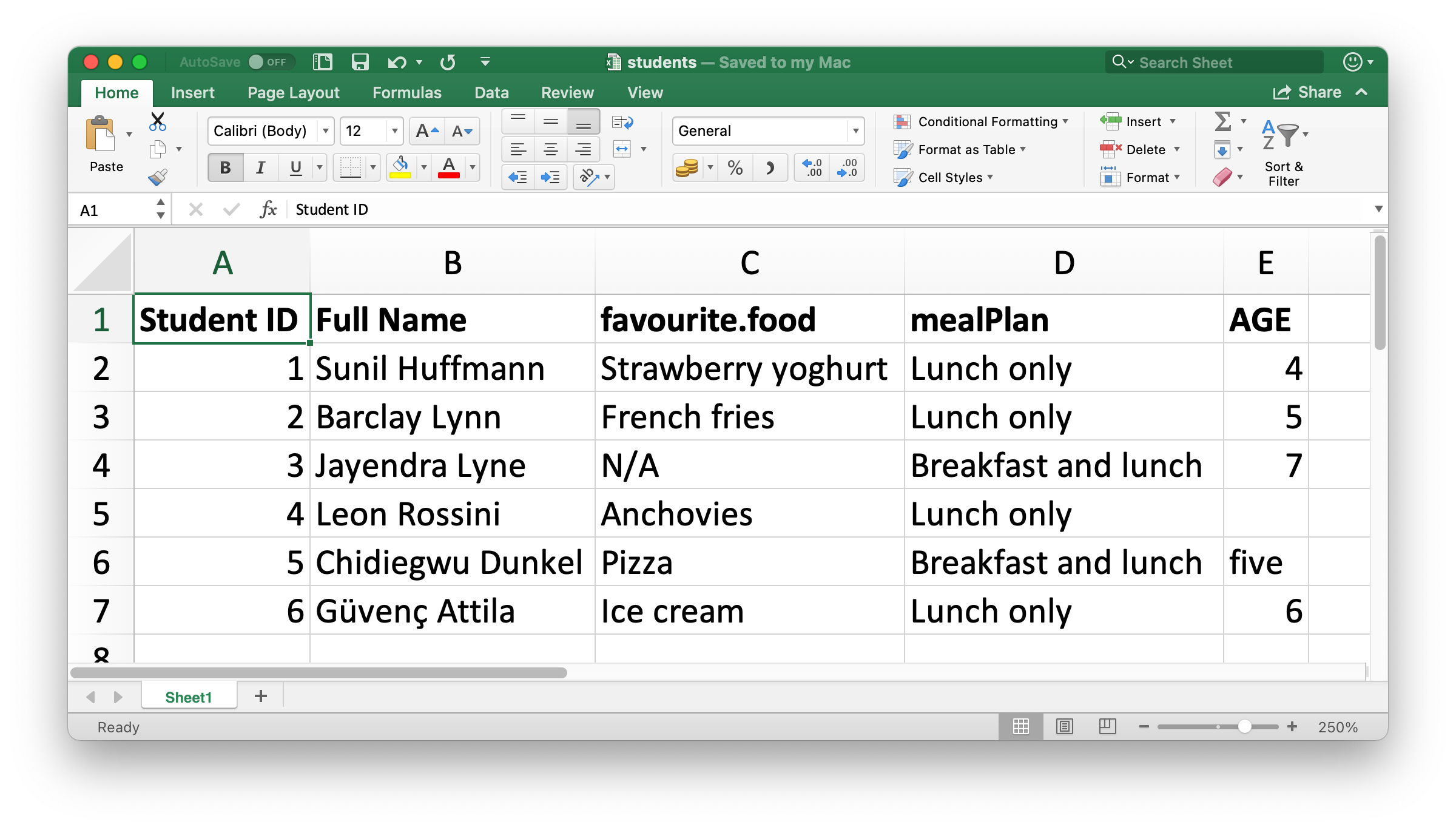
O primeiro argumento da read_excel() é o caminho (path) do arquivo a ser importado.
estudantes <- read_excel("data/estudantes.xlsx")read_excel() irá importar o arquivo como um tibble.
estudantes
#> # A tibble: 6 × 5
#> `ID Estudante` `Nome Completo` comida.favorita planoDeRefeição IDADE
#> <dbl> <chr> <chr> <chr> <chr>
#> 1 1 Igor Ribeiro Iogurte de Morango Apenas Almoço 4.0
#> 2 2 Fernanda Costa Batatas Fritas Apenas Almoço 5.0
#> 3 3 Daniel Lima N/A Café da Manhã e Al… 7.0
#> 4 4 Carla Oliveira Anchovas Apenas Almoço <NA>
#> 5 5 Fábio Pêra Pizza Café da Manhã e Al… cinco
#> 6 6 Bruno Souza Sorvete Apenas Almoço 6.0Temos seis estudantes nos dados e cinco variáveis para cada estudante. Entretanto, existem algumas coisas que devemos abordar neste conjunto de dados:
-
Os nomes das colunas estão com formato inconsistente. Você pode fornecer nomes que seguem um formato consistente; nós recomendamos o
snake_caseusando o argumentocol_names.read_excel( "data/estudantes.xlsx", col_names = c("estudante_id", "nome_completo", "comida_favorita", "refeicao_plano", "idade") ) #> # A tibble: 7 × 5 #> estudante_id nome_completo comida_favorita refeicao_plano idade #> <chr> <chr> <chr> <chr> <chr> #> 1 ID Estudante Nome Completo comida.favorita planoDeRefeição IDADE #> 2 1.0 Igor Ribeiro Iogurte de Morango Apenas Almoço 4.0 #> 3 2.0 Fernanda Costa Batatas Fritas Apenas Almoço 5.0 #> 4 3.0 Daniel Lima N/A Café da Manhã e Almoço 7.0 #> 5 4.0 Carla Oliveira Anchovas Apenas Almoço <NA> #> 6 5.0 Fábio Pêra Pizza Café da Manhã e Almoço cinco #> 7 6.0 Bruno Souza Sorvete Apenas Almoço 6.0Infelizmente, apenas isto não é o suficiente. Temos agora o nome das variáveis como gostaríamos, mas o que era anteriormente a linha de cabeçalho passou a aparecer nos dados como a primeira linha das observações. Você pode pular explicitamente esta linha usando o argumento
skip.read_excel( "data/estudantes.xlsx", col_names = c("estudante_id", "nome_completo", "comida_favorita", "refeicao_plano", "idade"), skip = 1 ) #> # A tibble: 6 × 5 #> estudante_id nome_completo comida_favorita refeicao_plano idade #> <dbl> <chr> <chr> <chr> <chr> #> 1 1 Igor Ribeiro Iogurte de Morango Apenas Almoço 4.0 #> 2 2 Fernanda Costa Batatas Fritas Apenas Almoço 5.0 #> 3 3 Daniel Lima N/A Café da Manhã e Almoço 7.0 #> 4 4 Carla Oliveira Anchovas Apenas Almoço <NA> #> 5 5 Fábio Pêra Pizza Café da Manhã e Almoço cinco #> 6 6 Bruno Souza Sorvete Apenas Almoço 6.0 -
Na coluna
comida_favorita, uma das observações está comoN/A, que significa “não disponível” (not available) mas essa forma não é reconhecida como um valor não disponível (NA) do R (veja a diferença entre esteN/Ae o presente naidadedo quarto estudante da lista). Você pode definir quais cadeias de caracteres (strings) devem ser reconhecidas pelo R comoNAutilizando o argumentona. Por padrão, apenas""(string vazia, ou, quando trabalhando com uma planilha, uma célula vazia ou com a fórmula=NA()) é reconhecida como umNA.read_excel( "data/estudantes.xlsx", col_names = c("estudante_id", "nome_completo", "comida_favorita", "refeicao_plano", "idade"), skip = 1, na = c("", "N/A") ) #> # A tibble: 6 × 5 #> estudante_id nome_completo comida_favorita refeicao_plano idade #> <dbl> <chr> <chr> <chr> <chr> #> 1 1 Igor Ribeiro Iogurte de Morango Apenas Almoço 4.0 #> 2 2 Fernanda Costa Batatas Fritas Apenas Almoço 5.0 #> 3 3 Daniel Lima <NA> Café da Manhã e Almoço 7.0 #> 4 4 Carla Oliveira Anchovas Apenas Almoço <NA> #> 5 5 Fábio Pêra Pizza Café da Manhã e Almoço cinco #> 6 6 Bruno Souza Sorvete Apenas Almoço 6.0 -
Um outro ponto que devemos observar é que a coluna
idadeé importada como uma variável texto, quando, na realidade, deveria ser numérica. Assim como naread_csv()e outras funções que importam dados de arquivos texto, você pode passar o argumentocol_typespara aread_excel()e especificar os tipos das colunas das variáveis que você está importanto. Porém, a sintaxe é um pouco diferente. Suas opções são:"skip","guess","logical","numeric","date","text"ou"list".read_excel( "data/estudantes.xlsx", col_names = c("estudante_id", "nome_completo", "comida_favorita", "refeicao_plano", "idade"), skip = 1, na = c("", "N/A"), col_types = c("numeric", "text", "text", "text", "numeric") ) #> Warning: Expecting numeric in E6 / R6C5: got 'cinco' #> # A tibble: 6 × 5 #> estudante_id nome_completo comida_favorita refeicao_plano idade #> <dbl> <chr> <chr> <chr> <dbl> #> 1 1 Igor Ribeiro Iogurte de Morango Apenas Almoço 4 #> 2 2 Fernanda Costa Batatas Fritas Apenas Almoço 5 #> 3 3 Daniel Lima <NA> Café da Manhã e Almoço 7 #> 4 4 Carla Oliveira Anchovas Apenas Almoço NA #> 5 5 Fábio Pêra Pizza Café da Manhã e Almoço NA #> 6 6 Bruno Souza Sorvete Apenas Almoço 6Porém, apenas isso também não produz o resultado desejado. Definindo que
idadedeve ser numérica, nós transformamos a célula com um valor não-numérico (aquela com valorcinco) em umNA. Neste caso, você deve importaridadecomo"text"e então fazer a mundança após os dados estarem carregados no R.estudantes <- read_excel( "data/estudantes.xlsx", col_names = c("estudante_id", "nome_completo", "comida_favorita", "refeicao_plano", "idade"), skip = 1, na = c("", "N/A"), col_types = c("numeric", "text", "text", "text", "text") ) estudantes <- estudantes |> mutate( idade = if_else(idade == "cinco", "5", idade), idade = parse_number(idade) ) estudantes #> # A tibble: 6 × 5 #> estudante_id nome_completo comida_favorita refeicao_plano idade #> <dbl> <chr> <chr> <chr> <dbl> #> 1 1 Igor Ribeiro Iogurte de Morango Apenas Almoço 4 #> 2 2 Fernanda Costa Batatas Fritas Apenas Almoço 5 #> 3 3 Daniel Lima <NA> Café da Manhã e Almoço 7 #> 4 4 Carla Oliveira Anchovas Apenas Almoço NA #> 5 5 Fábio Pêra Pizza Café da Manhã e Almoço 5 #> 6 6 Bruno Souza Sorvete Apenas Almoço 6
Foram necessários vários passos com tentativas e erros para importar os dados da maneira que precisávamos, e isto não é algo inesperado. A ciência de dados é um processo iterativo, e este processo de iteração pode ser ainda mais entediante quando importamos dados de planilhas se comparado a quando importamos dados de arquivos textos (dados retangulares) pois os humanos tendem a inserir dados nas planilhas e usá-las não apenas para armazenar os dados, mas também para compartilhamento e communicação.
Não há como saber exatamente como os dados serão importados até você carregá-los e dar uma olhada. Bem, na verdade há um jeito. Você pode abrir o arquivo no Excel e dar uma olhada. Se você for fazer isso, recomendamos fazer uma cópia do arquivo original e usar a outra cópia para navegar pelo arquivo, deixando a primeira inalterada para ser carregada pelo R. Isto certificará que você não irá sobreescrever acidentalmente nada na planilha enquanto a inspeciona. Você também não precisa ter medo de fazer o que fizemos aqui: Carregar o arquivo, dar uma olhada, fazer os ajustes no seu código, carregar novamente e repetir tudo até que esteja contente com o resultado.
20.2.4 Importando planilhas
Uma característica importante que distingue arquivos do Excel de arquivos texto, é a noção de várias planilhas (ou abas) dentro do mesmo arquivo. A Figura 20.2 mostra um arquivo Excel com várias planilhas. Os dados são do pacote palmerpenguins, e você pode fazer o download como um arquivo Excel em https://github.com/cienciadedatos/pt-r4ds/raw/traducao-pt-2ed/data/pinguins.xlsx. Cada planilha (ou aba) contém informações de pinguins de diferentes ilhas onde os dados foram coletados.
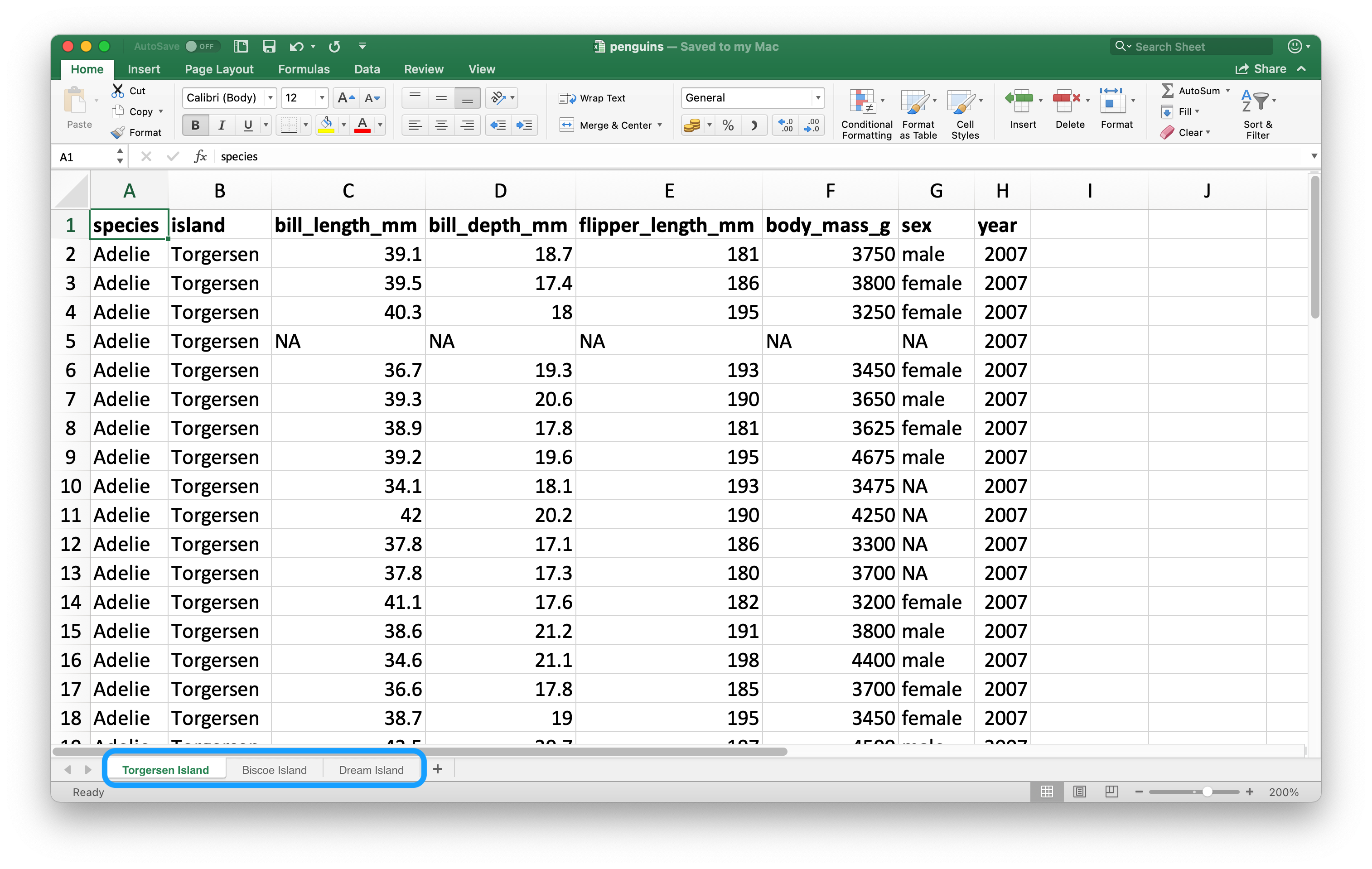
Você pode importar uma única planilha usando o argumento sheet na função read_excel(). Por padrão, o que utilizamos até agora, a primeira planilha é importada.
read_excel("data/pinguins.xlsx", sheet = "Ilha Torgersen")
#> New names:
#> • `` -> `...1`
#> # A tibble: 52 × 9
#> ...1 especie ilha comprimento_bico profundidade_bico
#> <chr> <chr> <chr> <dbl> <dbl>
#> 1 1 Pinguim-de-adélia Torgersen 39.1 18.7
#> 2 2 Pinguim-de-adélia Torgersen 39.5 17.4
#> 3 3 Pinguim-de-adélia Torgersen 40.3 18
#> 4 4 Pinguim-de-adélia Torgersen NA NA
#> 5 5 Pinguim-de-adélia Torgersen 36.7 19.3
#> 6 6 Pinguim-de-adélia Torgersen 39.3 20.6
#> # ℹ 46 more rows
#> # ℹ 4 more variables: comprimento_nadadeira <dbl>, massa_corporal <dbl>, …Algumas variáveis que parecem conter dados numéricos, são importadas como caracteres (texto) devido à cadeia de caractere "NA" não ser reconhecida como um verdadeiro NA.
pinguins_torgersen <- read_excel("data/pinguins.xlsx", sheet = "Ilha Torgersen", na = "NA")
#> New names:
#> • `` -> `...1`
pinguins_torgersen
#> # A tibble: 52 × 9
#> ...1 especie ilha comprimento_bico profundidade_bico
#> <chr> <chr> <chr> <dbl> <dbl>
#> 1 1 Pinguim-de-adélia Torgersen 39.1 18.7
#> 2 2 Pinguim-de-adélia Torgersen 39.5 17.4
#> 3 3 Pinguim-de-adélia Torgersen 40.3 18
#> 4 4 Pinguim-de-adélia Torgersen NA NA
#> 5 5 Pinguim-de-adélia Torgersen 36.7 19.3
#> 6 6 Pinguim-de-adélia Torgersen 39.3 20.6
#> # ℹ 46 more rows
#> # ℹ 4 more variables: comprimento_nadadeira <dbl>, massa_corporal <dbl>, …Alternativamente, você pode usar excel_sheets() para obter informações de todas as planilhas presentes em um arquivo Excel, e então importar aquela(s) em que você está interessado.
excel_sheets("data/pinguins.xlsx")
#> [1] "Ilha Biscoe" "Ilha Dream" "Ilha Torgersen"Assim que você souber o(s) nome(s) da(s) planilha(s), você pode importá-la(s) individualmente com read_excel().
pinguins_biscoe <- read_excel("data/pinguins.xlsx", sheet = "Ilha Biscoe", na = "NA")
#> New names:
#> • `` -> `...1`
pinguins_dream <- read_excel("data/pinguins.xlsx", sheet = "Ilha Dream", na = "NA")
#> New names:
#> • `` -> `...1`Neste caso, o conjunto de dados completo está espalhado entre três planilhas distintas no arquivo. Cada planilha tem o mesmo número de colunas, mas diferentes números de linhas.
Nós podemos uní-las usando bind_rows().
pinguins <- bind_rows(pinguins_torgersen, pinguins_biscoe, pinguins_dream)
pinguins
#> # A tibble: 344 × 9
#> ...1 especie ilha comprimento_bico profundidade_bico
#> <chr> <chr> <chr> <dbl> <dbl>
#> 1 1 Pinguim-de-adélia Torgersen 39.1 18.7
#> 2 2 Pinguim-de-adélia Torgersen 39.5 17.4
#> 3 3 Pinguim-de-adélia Torgersen 40.3 18
#> 4 4 Pinguim-de-adélia Torgersen NA NA
#> 5 5 Pinguim-de-adélia Torgersen 36.7 19.3
#> 6 6 Pinguim-de-adélia Torgersen 39.3 20.6
#> # ℹ 338 more rows
#> # ℹ 4 more variables: comprimento_nadadeira <dbl>, massa_corporal <dbl>, …No Capítulo 26 falaremos sobre outras maneiras de fazer este tipo de coisa sem repetir código.
20.2.5 Importando parte de uma planilha
Uma vez que muitas pessoas usam arquivos do Excel tanto pra apresentação quanto para armazenamento dos dados, é muito comum encontrarmos células em uma planilha que não fazem parte dos dados que você quer importar para o R. A Figura 20.3 mostra um exemplo: no centro da planilha temos algo que se parece com um data frame, mas existem estranhos textos acima e abaixo dos dados.
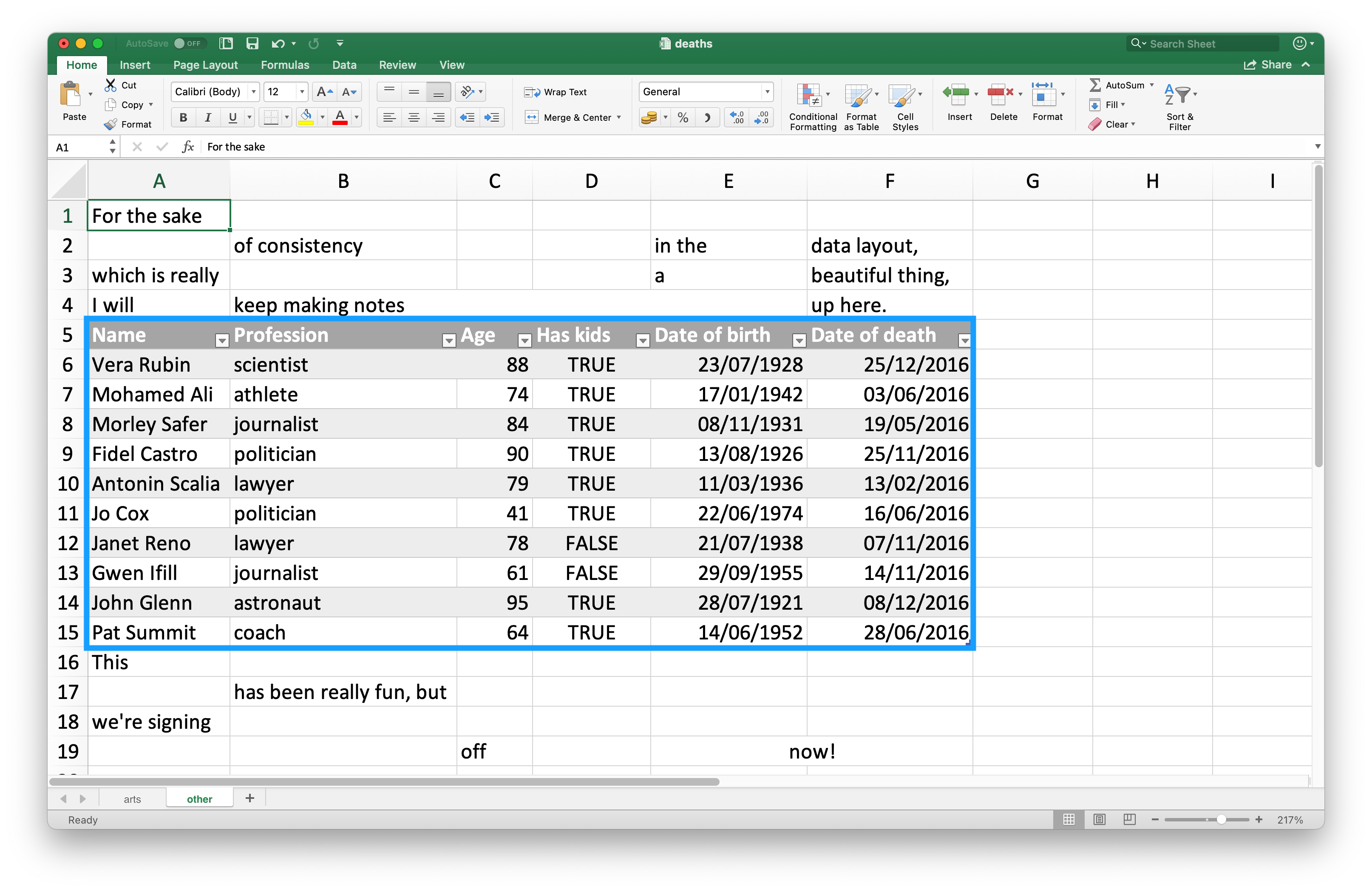
Esta planilha é um dos exemplos fornecidos com o pacote readxl. Você pode usar a função readxl_example() para localizar esta planilha no diretório em que o pacote foi instalado em seu computador. Esta função retorna o caminho para o arquivo do Excel, que você pode importar usando a read_excel() como de costume.
obitos_caminho <- readxl_example("deaths.xlsx")
obitos <- read_excel(obitos_caminho)
#> New names:
#> • `` -> `...2`
#> • `` -> `...3`
#> • `` -> `...4`
#> • `` -> `...5`
#> • `` -> `...6`
obitos
#> # A tibble: 18 × 6
#> `Lots of people` ...2 ...3 ...4 ...5 ...6
#> <chr> <chr> <chr> <chr> <chr> <chr>
#> 1 simply cannot resi… <NA> <NA> <NA> <NA> some notes
#> 2 at the top <NA> of their spreadsh…
#> 3 or merging <NA> <NA> <NA> cells
#> 4 Name Profession Age Has kids Date of birth Date of death
#> 5 David Bowie musician 69 TRUE 17175 42379
#> 6 Carrie Fisher actor 60 TRUE 20749 42731
#> # ℹ 12 more rowsAs primeiras três linhas e as quatro linhas no final, não fazem parte do data frame. É possível eliminar estas linhas extras usando os argumentos skip e n_max, mas recomendamos utilizar intervalos (range) de células. No Excel, a célula superior esquerda é a A1. Conforme você se move pelas colunas para a direita, o título da célula segue a sequência do alfabeto, ou seja: B1, C1, etc. E conforme você se move para baixo na coluna, o número da célula aumenta, ex: A2, A3, etc.
Aqui, os dados que desejamos importar começam na célula A5 e terminam na célula F15. Na notação da planilha, temos A5:F15, que fornecemos para o argumento range:
read_excel(obitos_caminho, range = "A5:F15")
#> # A tibble: 10 × 6
#> Name Profession Age `Has kids` `Date of birth`
#> <chr> <chr> <dbl> <lgl> <dttm>
#> 1 David Bowie musician 69 TRUE 1947-01-08 00:00:00
#> 2 Carrie Fisher actor 60 TRUE 1956-10-21 00:00:00
#> 3 Chuck Berry musician 90 TRUE 1926-10-18 00:00:00
#> 4 Bill Paxton actor 61 TRUE 1955-05-17 00:00:00
#> 5 Prince musician 57 TRUE 1958-06-07 00:00:00
#> 6 Alan Rickman actor 69 FALSE 1946-02-21 00:00:00
#> # ℹ 4 more rows
#> # ℹ 1 more variable: `Date of death` <dttm>20.2.6 Tipos de dados
Em arquivos CSV, todos os valores são strings”. Isto não é particularmente verdadeiro para os dados, mas é simples: tudo é uma string”.
Os dados intrínsecos nas planilhas Excel são mais complexos. Uma célula pode conter uma dessas quatro coisas:
Um booleano, como
TRUE,FALSE, ouNA.Um número, como “10” ou “10.5”.
Uma data/horário (datetime), que pode conter algo como “11/1/21” ou “11/1/21 3:00 PM”.
Um texto (string), como “dez”.
Quando trabalhamos com dados de planilhas, é importante ter em mente que os dados intrínsecos podem ser muito diferentes daquilo que vemos em uma célula. Por exemplo, o Excel não tem a noção de ‘inteiro’ (integer). Todos os números são armazenados como ponto flutuante (floating points), mas você pode optar em mostrar os dados de uma forma personalizada de casas decimais. Da mesma maneira, datas são na verdade armazenadas como números, especificamente número de segundos desde 1º de Janeiro de 1970. Você pode personalizar como você quer mostrar as datas no Excel aplicando formatações. Para confundir ainda mais, também é possível ter algo que se parece com um número, mas é na verdade uma string (por exemplo: , digite '10 em uma célula no Excel).
Estas diferenças em como os dados intrínsecos são armazenados vs. como eles são mostrados na tela podem causar surpresas quando os dados são importados para o R. Por padrão, readxl tentará adivinhar o tipo de dado de uma determinada coluna. Um fluxo de trabalho recomendado é deixar o readxl adivinhar os tipos das colunas, confirmar se você está contente com os tipos sugeridos, e caso não estiver, importar novamente especificando o argumento col_types como mostrado na Seção 20.2.3.
Outro desafio é quando você tem uma coluna na planilha do Excel que tem uma mistura de diferentes tipos: algumas células são numéricas, outras contém texto, outras contém datas. Quando importamos esses dados para o R, o readxl deve tomar algumas decisões. Nestes casos, você pode definir o tipo para esta coluna como "list", o qual importará a coluna como uma lista de vetores de tamanho 1, onde o tipo de cada elemento do vetor é sugerido.
Algumas vezes os dados são armazenados de forma mais exótica, como cores de fundo da célula, ou com texto em negrito ou não. Nestes casos, você pode achar útil o pacote tidyxl. Veja https://nacnudus.github.io/spreadsheet-munging-strategies/ para mais estratégias de trabalho com dados não tabulares vindos do Excel.
20.2.7 Exportando para Excel
Vamos criar um pequeno conjunto de dados (tibble) que iremos exportar. Note que item é um fator (factor) e quantidade é um inteiro (integer).
Você pode gravar estes dados em disco como um arquivo do Excel usando a função write_xlsx() do pacote writexl package:
write_xlsx(doces_vendas, path = "data/doces-vendas.xlsx")A Figura 20.4 mostra como os dados aparecem no Excel. Note que os nomes das colunas também aparecem em negrito. Isto pode ser modificado definindo como FALSE os argumentos col_names e format_headers.
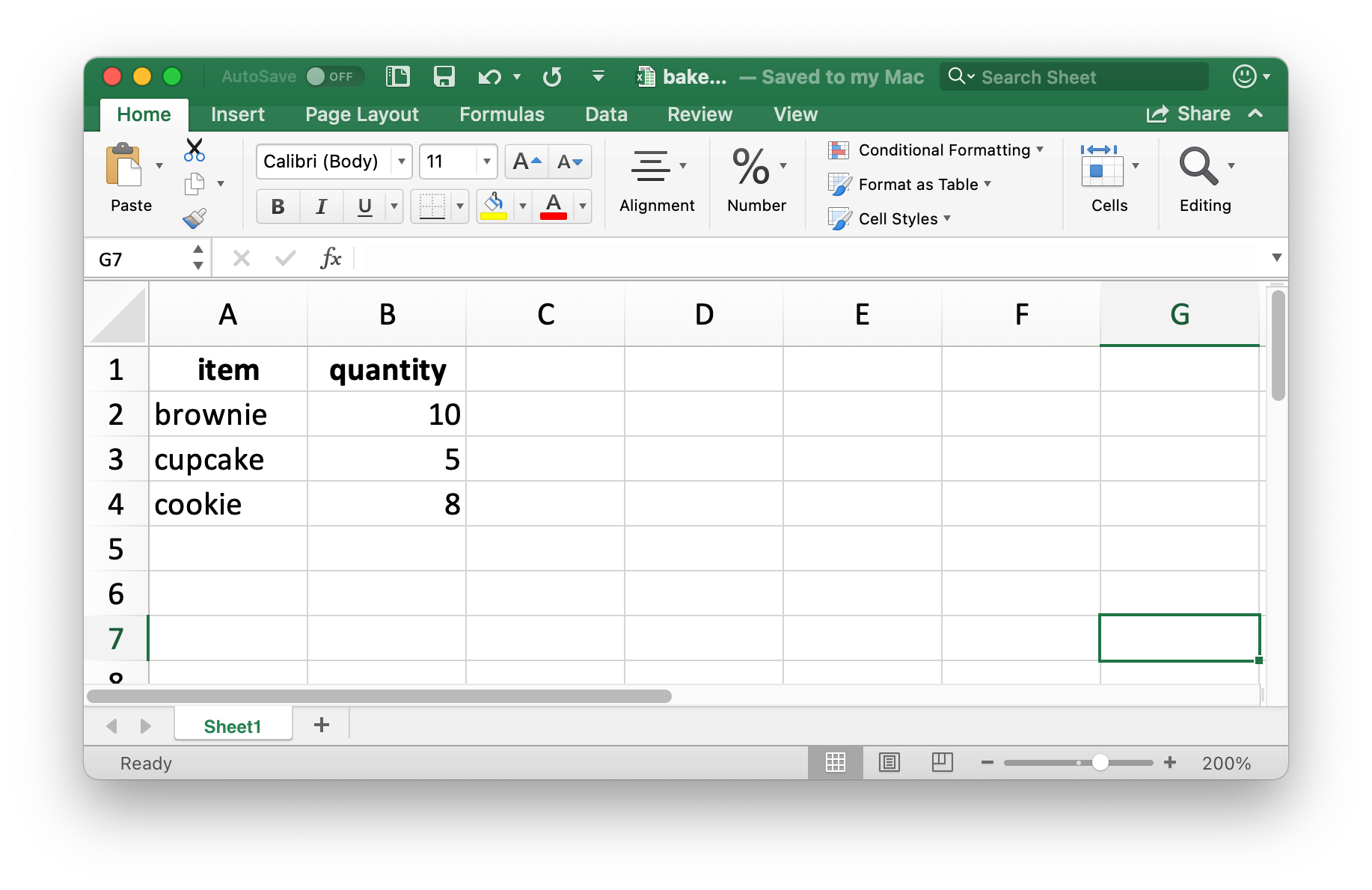
Assim como acontece quando importamos dados de um CSV, as informações sobre os tipos de dados são perdidas quando importamos os dados novamente. Isto torna os arquivos do Excel uma fonte não confiável para armazenar resultados parciais. Para alternativas, veja Seção 7.5.
read_excel("data/doces-vendas.xlsx")
#> # A tibble: 3 × 2
#> item quantidade
#> <chr> <dbl>
#> 1 brownie 10
#> 2 cupcake 5
#> 3 cookie 820.2.8 Saídas formatadas
O pacote writexl é uma solução simplificada para criar uma simples planilha do Excel, mas se você estiver interessado em características adicionais como escrever em uma planilha dentro de um arquivo e estilizá-la, você pode querer utilizar o pacote openxlsx. Não entraremos nos detalhes deste pacote aqui, mas recomendamos ler https://ycphs.github.io/openxlsx/articles/Formatting.html para uma extensa discussão sobre outras funcionalidades de formatação de dados do R para o Excel usando o openxlsx.
Observe que este pacote não faz parte do tidyverse, portanto as funções e fluxos de trabalho podem não ser familiares. Por exemplo, os nomes das funções usam camelCase, várias funções não podem compor um pipeline, e os argumentos tendem a seguir ordens diferentes daquelas do tidyverse. Entretanto, tudo bem. Conforme seu aprendizado e uso do R expandem para além deste livro, você encontrará vários outros estilos em diversos pacotes disponíveis para atingir seus objetivos específicos no R. Uma boa forma de se familiarizar com o estilo de código em um novo pacote é executar alguns exemplos fornecidos na documentação das funções, sentir a sintaxe e formatos de saída, assim como ler qualquer vignette que acompanha o pacote.
20.2.9 Exercícios
-
Em um arquivo do Excel, crie o seguinte conjunto de dados e salve como
pesquisa.xlsx. Alternativamente, você pode baixar aqui como arquivo do Excel.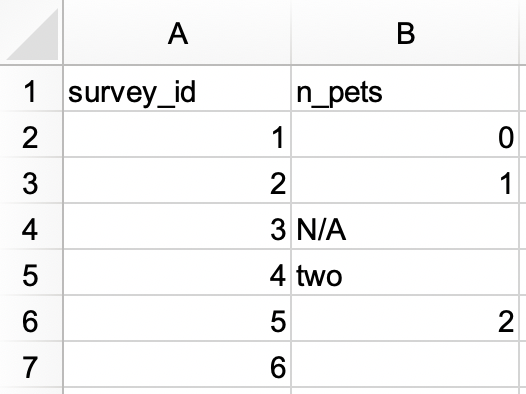
Depois, importe para o R tendo
pesquisa_idcomo uma variável texto en_animais_estimacaocomo uma variável numérica.#> # A tibble: 6 × 2 #> pesquisa_id n_animais_estimacao #> <chr> <dbl> #> 1 1 0 #> 2 2 1 #> 3 3 NA #> 4 4 2 #> 5 5 2 #> 6 6 NA -
Em outro arquivo do Excel, crie o seguinte conjunto de dados e salve como
lista.xlsx. Alternativamente, você pode baixar aqui como arquivo do Excel.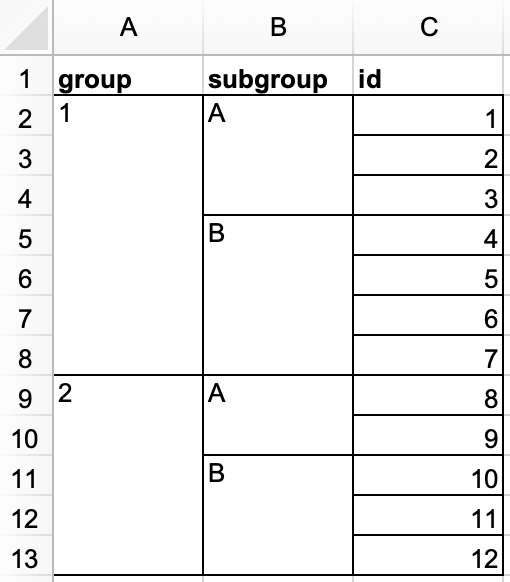
Depois, importe-o para o R. O conjunto de dados resultante deve ser nomeado como
listae deve se parecer com o que é mostrado a seguir.#> # A tibble: 12 × 3 #> grupo subgrupo id #> <dbl> <chr> <dbl> #> 1 1 A 1 #> 2 1 A 2 #> 3 1 A 3 #> 4 1 B 4 #> 5 1 B 5 #> 6 1 B 6 #> 7 1 B 7 #> 8 2 A 8 #> 9 2 A 9 #> 10 2 B 10 #> 11 2 B 11 #> 12 2 B 12 -
Em um novo arquivo do Excel, crie o seguinte conjunto de dados e salve como
vendas.xlsx. Alternativamente, você pode baixar aqui como arquivo do Excel.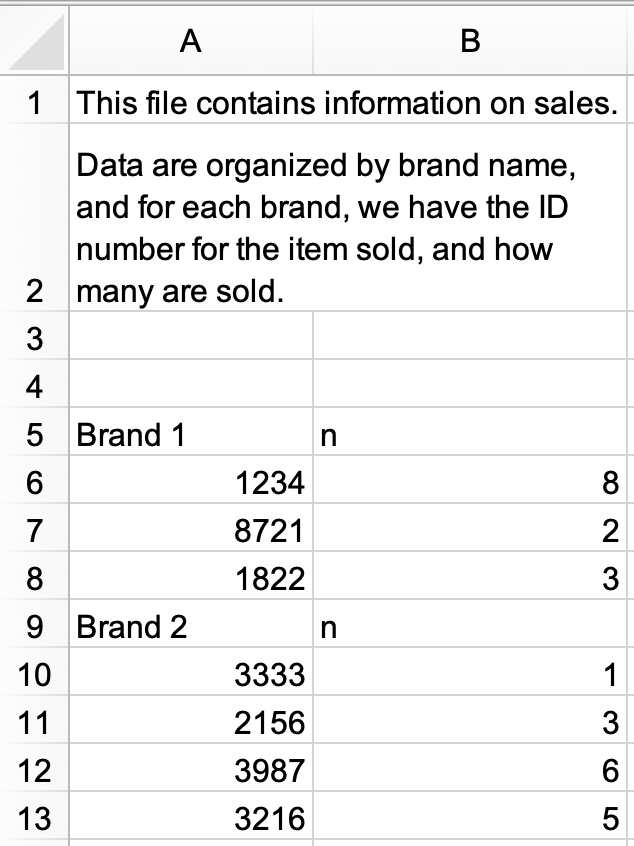
a. Importar
vendas.xlsxe salvar comovendas. O conjunto de dados deve se parecer com o que é mostrado a seguir, comidencomo nomes das colunas e com 9 linhas.#> # A tibble: 9 × 2 #> id n #> <chr> <chr> #> 1 Marca 1 n #> 2 1234 8 #> 3 8721 2 #> 4 1822 3 #> 5 Marca 2 n #> 6 3333 1 #> 7 2156 3 #> 8 3987 6 #> 9 3216 5b. Modifique
vendasde forma a ficar organizado (tidy) com três colunas (marca,id, en) e 7 linhas de dados. Note queidensão numéricas,marcaé uma variável texto (ou caractere).#> # A tibble: 7 × 3 #> marca id n #> <chr> <dbl> <dbl> #> 1 Marca 1 1234 8 #> 2 Marca 1 8721 2 #> 3 Marca 1 1822 3 #> 4 Marca 2 3333 1 #> 5 Marca 2 2156 3 #> 6 Marca 2 3987 6 #> 7 Marca 2 3216 5 Recrie o conjunto de dados
doces_vendas, exporte para um arquivo do Excel usando a funçãowrite.xlsx()do pacote openxlsx.No Capítulo 7 você aprendeu sobre a função
janitor::clean_names()para transformar os nomes das colunas em snake case. Importe o arquivoestudantes.xlsxque foi introduzido anteriormente nesta seção e use a função para “limpar” os nomes das colunas.O que acontece se você tentar importar um arquivo com a extensão
.xlsxcomread_xls()?
20.3 Planilhas Google (Google Sheets)
O Planilhas Google (Google Sheets) é um outro programa de planilha amplamente utilizado. É gratuito e acessado via navegador (web-based). Assim como o Excel, no Planilhas Google, os dados são armazenados em planilhas dentro de um arquivo.
20.3.1 Pré-requisitos
Esta seção também será focada em planilhas, mas desta vez você irá carregar os dados do Planilhas Google com o pacote googlesheets4. Este pacote também faz parte dos componentes secundários (non-core) do tidyverse, portanto devemos carregá-lo explicitamente.
Uma breve nota sobre o nome do pacote: googlesheets4 usa a versão 4 da API do Planilhas Google para fornecer uma interface do Planilhas Google para o R, por isso este nome.
20.3.2 Iniciando
A principal função do pacote googlesheets4 é a read_sheet(), a qual importa uma planilha do Google a partir de uma URL ou id do arquivo. Esta função também pode ser chamada pelo nome de range_read().
Você também pode criar uma nova planilha com a gs4_create() ou escrever em uma planilha já existente com a sheet_write() e semelhantes.
Nesta seção trabalharemos com os mesmos conjuntos de dados utilizados na seção sobre arquivos do Excel para destacar semelhanças e diferenças entre o fluxo de trabalho de importação de dados do Excel e do Planilhas Google. Os pacotes readxl e googlesheets4 foram desenhados para terem funcionalidades semelhantes ao pacote readr, o qual fornece a função read_csv() que você viu no Capítulo 7. Existem muitas tarefas que podem ser realizadas apenas trocando read_excel() por read_sheet(). Entretanto, você verá que o Excel e o Planilhas Google não se comportam extamente da mesma maneira, por isso, algumas chamadas de funções podem ser diferentes.
20.3.3 Importando do Planilhas Google
A Figura 20.5 mostra como é a planilha do Google que iremos importar para o R. Este é o mesmo conjunto de dados da Figura 20.1, exceto que está armazenado no Planilhas Google ao invés do Excel.
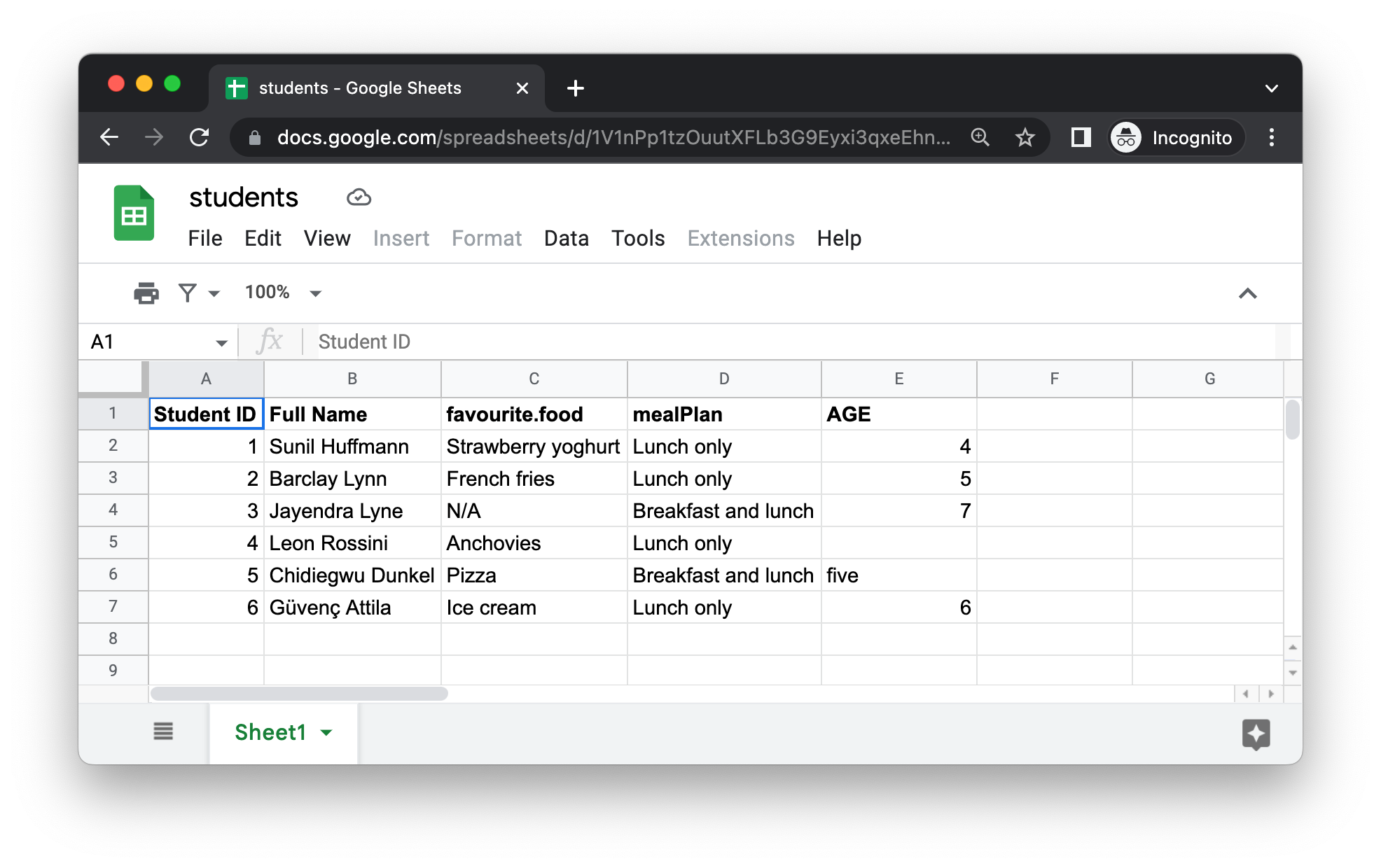
O primeiro argumento da read_sheet() é a URL do arquivo a ser importado, e a função retorna um tibble:
https://docs.google.com/spreadsheets/d/1V1nPp1tzOuutXFLb3G9Eyxi3qxeEhnOXUzL5_BcCQ0w. Estas URLs não são fáceis de se trabalhar, portanto frequentemente você irá preferir identificar uma planilha através do seu ID.
estudantes_planilha_id <- "1V1nPp1tzOuutXFLb3G9Eyxi3qxeEhnOXUzL5_BcCQ0w"
estudantes <- read_sheet(estudantes_planilha_id)
#> ✔ Reading from students.
#> ✔ Range Sheet1.
estudantes
#> # A tibble: 6 × 5
#> `Student ID` `Full Name` favourite.food mealPlan AGE
#> <dbl> <chr> <chr> <chr> <list>
#> 1 1 Sunil Huffmann Strawberry yoghurt Lunch only <dbl>
#> 2 2 Barclay Lynn French fries Lunch only <dbl>
#> 3 3 Jayendra Lyne N/A Breakfast and lunch <dbl>
#> 4 4 Leon Rossini Anchovies Lunch only <NULL>
#> 5 5 Chidiegwu Dunkel Pizza Breakfast and lunch <chr>
#> 6 6 Güvenç Attila Ice cream Lunch only <dbl>Assim como fizemos na read_excel(), você pode fornecer nomes para as colunas, strings de valores não disponíveis (NA) e os tipos das colunas para a read_sheet().
estudantes <- read_sheet(
estudantes_planilha_id,
col_names = c("estudante_id", "nome_completo", "comida_favorita", "refeicao_plano", "idade"),
skip = 1,
na = c("", "N/A"),
col_types = "dcccc"
)
#> ✔ Reading from students.
#> ✔ Range 2:10000000.
estudantes
#> # A tibble: 6 × 5
#> estudante_id nome_completo comida_favorita refeicao_plano idade
#> <dbl> <chr> <chr> <chr> <chr>
#> 1 1 Sunil Huffmann Strawberry yoghurt Lunch only 4
#> 2 2 Barclay Lynn French fries Lunch only 5
#> 3 3 Jayendra Lyne <NA> Breakfast and lunch 7
#> 4 4 Leon Rossini Anchovies Lunch only <NA>
#> 5 5 Chidiegwu Dunkel Pizza Breakfast and lunch five
#> 6 6 Güvenç Attila Ice cream Lunch only 6Note que definimos os tipos das colunas de uma forma um pouco diferente aqui, usando códigos abreviados. Por exemplo, “dcccc” significa “double, character, character, character, character”.
Também é possível importar planilhas individuais do Planilhas Google. Para importar somente a planilha “Ilha Torgersen” da Planilha Pinguins do Planilhas Google:
pinguins_planilha_id <- "1aFu8lnD_g0yjF5O-K6SFgSEWiHPpgvFCF0NY9D6LXnY"
read_sheet(pinguins_planilha_id, sheet = "Torgersen Island")
#> ✔ Reading from penguins.
#> ✔ Range ''Torgersen Island''.
#> # A tibble: 52 × 8
#> species island bill_length_mm bill_depth_mm flipper_length_mm
#> <chr> <chr> <list> <list> <list>
#> 1 Adelie Torgersen <dbl [1]> <dbl [1]> <dbl [1]>
#> 2 Adelie Torgersen <dbl [1]> <dbl [1]> <dbl [1]>
#> 3 Adelie Torgersen <dbl [1]> <dbl [1]> <dbl [1]>
#> 4 Adelie Torgersen <chr [1]> <chr [1]> <chr [1]>
#> 5 Adelie Torgersen <dbl [1]> <dbl [1]> <dbl [1]>
#> 6 Adelie Torgersen <dbl [1]> <dbl [1]> <dbl [1]>
#> # ℹ 46 more rows
#> # ℹ 3 more variables: body_mass_g <list>, sex <chr>, year <dbl>Você pode obter todos os nomes de planilhas de dentro de um arquivo do Planilhas Google com sheet_names():
sheet_names(pinguins_planilha_id)
#> [1] "Torgersen Island" "Biscoe Island" "Dream Island"Finalmente, assim como na read_excel(), podemos importar um intervalo de uma planilha definindo o argumento range na função read_sheet(). Observe que também estamos utilizando a função gs4_example() para localizar a planilha de exemplo que vem junto com o pacote googlesheets4.
obitos_url <- gs4_example("deaths")
obitos <- read_sheet(obitos_url, range = "A5:F15")
#> ✔ Reading from deaths.
#> ✔ Range A5:F15.
obitos
#> # A tibble: 10 × 6
#> Name Profession Age `Has kids` `Date of birth`
#> <chr> <chr> <dbl> <lgl> <dttm>
#> 1 David Bowie musician 69 TRUE 1947-01-08 00:00:00
#> 2 Carrie Fisher actor 60 TRUE 1956-10-21 00:00:00
#> 3 Chuck Berry musician 90 TRUE 1926-10-18 00:00:00
#> 4 Bill Paxton actor 61 TRUE 1955-05-17 00:00:00
#> 5 Prince musician 57 TRUE 1958-06-07 00:00:00
#> 6 Alan Rickman actor 69 FALSE 1946-02-21 00:00:00
#> # ℹ 4 more rows
#> # ℹ 1 more variable: `Date of death` <dttm>20.3.4 Exportando para o Planilhas Google
Você pode exportar dados do R para o Planilhas Google com a função write_sheet(). O primeiro argumento é o conjuntos de dados a ser exportado, o segundo argumento é o nome (ou outro identificador) da planilha a ser gravado no Planilhas Google:
write_sheet(doces_vendas, ss = "doces-vendas")Se você quiser exportar para uma planilha específica dentro de um arquivo do Planilhas Google, você poderá fazê-lo especificando o argumento sheet também.
write_sheet(doces_vendas, ss = "doces-vendas", sheet = "Vendas")20.3.5 Autenticação
Apesar de você poder importar uma planilha pública com sua conta do Google e a função gs4_deauth(), importar uma planilha privada ou exportar para uma requer autenticação para que o pacote googlesheets4 possa acessar e gerenciar suas Planilhas Google.
Quando você tenta acessar uma planilha que requer autenticação, o googlesheets4 irá te redirecionar para um navegador web e pedir sua conta do Google para obter a permissão de operar as planilhas em seu lugar. Entretanto, se você quiser definir uma conta específica, escopo de autenticação, etc, você pode fazer através da gs4_auth(), ex: gs4_auth(email = "meu@exemplo.com"), o qual irá forçar o uso de um token associado a este email específico. Para mais informações sobre autenticação, recomendamos ler a documentação do googlesheets4 (auth vignette) em https://googlesheets4.tidyverse.org/articles/auth.html.
20.3.6 Exercícios
Importe o conjunto de dados
estudantesvisto anteriormente neste capítulo do Excel e do Planilhas Google, sem argumentos adicionais usando as funçõesread_excel()eread_sheet(). Os data frames resultantes são idênticos no R? Se não, quais as diferenças?Importe a planilha chamada pesquisa do Planilhas Google de https://pos.it/r4ds-survey, tendo
pesquisa_idcomo uma variável texto (caractere) en_animais_estimacaocomo numérica.-
Importe do Planilhas Google o arquivo chamado lista de https://pos.it/r4ds-roster. O data frame resultante deve se chamar
listae deve se parecer como mostrado abaixo.#> # A tibble: 12 × 3 #> group subgroup id #> <dbl> <chr> <dbl> #> 1 1 A 1 #> 2 1 A 2 #> 3 1 A 3 #> 4 1 B 4 #> 5 1 B 5 #> 6 1 B 6 #> 7 1 B 7 #> 8 2 A 8 #> 9 2 A 9 #> 10 2 B 10 #> 11 2 B 11 #> 12 2 B 12
20.4 Resumo
O Microsoft Excel e o Planilhas Google são dois sistemas de planilhas muito populares. Ser capaz de interagir com dados armazenados no Excel e Planilhas Google diretamente do R é um superpoder! Neste capítulo você aprendeu a importar dados para o R de planilhas do Excel usando a read_excel() do pacote readxl e do Planilhas Google usando a read_sheet() do pacote googlesheets4. Estas funções trabalham de forma muito parecidas e possuem argumentos similares para especificar nomes de colunas, valores não disponíveis (NA), pular linhas no início do arquivo que está importando, etc. Além disso, ambas funções permitem ler planilhas específicas de dentro dos respectivos arquivos.
Por outro lado, exportar para o Excel requer um pacote e função diferente (writexl::write_xlsx()) enquanto você pode exportar para o Planilhas Google com o mesmo pacote googlesheets4, com a função write_sheet().
No próximo capítulo, você aprenderá sobre uma fonte de dados diferente e como importar dados desta fonte para o R: banco de dados (databases).