23 Dados hierárquicos (rectangling)
23.1 Introdução
Neste capítulo, você aprenderá a arte da representação retangular dos dados (rectangling): pegar um dado que é fundamentalmente hierárquico ou baseado em uma estrutura de árvore (tree-like) e convertê-lo em um data frame retangular, composto por linhas e colunas. Isto é importante porque dados hierárquicos são surpreendentemente comuns, especialmente quando se trabalha com dados vindos da web.
Para aprender sobre representação retangular, você precisa aprender primeiro sobre listas, que são estruturas de dados que tornam os dados hierárquicos possíveis. Depois, você aprenderá sobre duas funções críticas do tidyr: tidyr::unnest_longer() e tidyr::unnest_wider(). Iremos então mostrar alguns estudos de caso, aplicando estas funções simples diversas vezes para resolver problemas reais. Concluiremos falando sobre JSON, a fonte mais frequente de conjuntos de dados hierárquicos e um formato comum para intercambio de dados na web.
23.1.1 Pré-requisitos
Neste capítulo, usaremos várias funções do tidyr, um pacote central do tidyverse. Usaremos também o pacote repurrrsive para nos fornecer alguns conjuntos de dados interessantes para praticar a representação retangular e concluiremos usando o pacote jsonlite para importar arquivos JSON para o R como listas.
23.2 Listas
Até agora você trabalhou com data frames que continham vetores simples como inteiros, números, caracteres, data_hora e fatores. Estes vetores são simples pois são homogêneos: cada elemento tem o mesmo tipo de dado. Se você quiser armazenar elementos de diferentes tipos no mesmo vetor, você precisará de uma lista, que pode ser criada com a função list():
x1 <- list(1:4, "a", TRUE)
x1
#> [[1]]
#> [1] 1 2 3 4
#>
#> [[2]]
#> [1] "a"
#>
#> [[3]]
#> [1] TRUEEm geral, é conveniente nomear os componentes ou elementos de uma lista, o que pode ser feito da mesma forma que nomeamos colunas de um tibble:
x2 <- list(a = 1:2, b = 1:3, c = 1:4)
x2
#> $a
#> [1] 1 2
#>
#> $b
#> [1] 1 2 3
#>
#> $c
#> [1] 1 2 3 4Até para estas listas simples, é necessário um espaço razoável para exibi-las no Console. Uma alternativa é usar str(), que gera uma visualização compacta da estrutura, tirando o foco de seu contéudo:
Como você pode ver, str() mostra cada elemento da lista em uma linha própria. Esta função mostra o nome, quando presente, seguido de uma abreviação do tipo e então os primeiros valores.
23.2.1 Hierarquia
Listas podem conter qualquer tipo de objeto, incluindo outras listas. Isto as tornam adequadas para representar estruturas hierárquicas (tree-like):
Isto é notoriamente diferente de c(), que gera um vetor achatado (flat):
Conforme as listas se tornam mais complexas, str() se torna mais útil, pois permite que você veja a hierarquia rapidamente:
Conforme as listas aumentam ainda mais e se tornam ainda mais complexas, str() pode começar a deixar de ser útil e você precisará mudar para a View()1. A Figura 23.1 mostra o resultado da chamada de View(x5). O visualizador começa mostrando o nível mais alto da lista, mas você pode expandir interativamente qualquer componente para ver mais, como na Figura 23.2. O RStudio também lhe mostra o código que você precisaria para acessar aquele elemento, como na Figura 23.3. Retornaremos a como este código funciona na Seção 27.3.
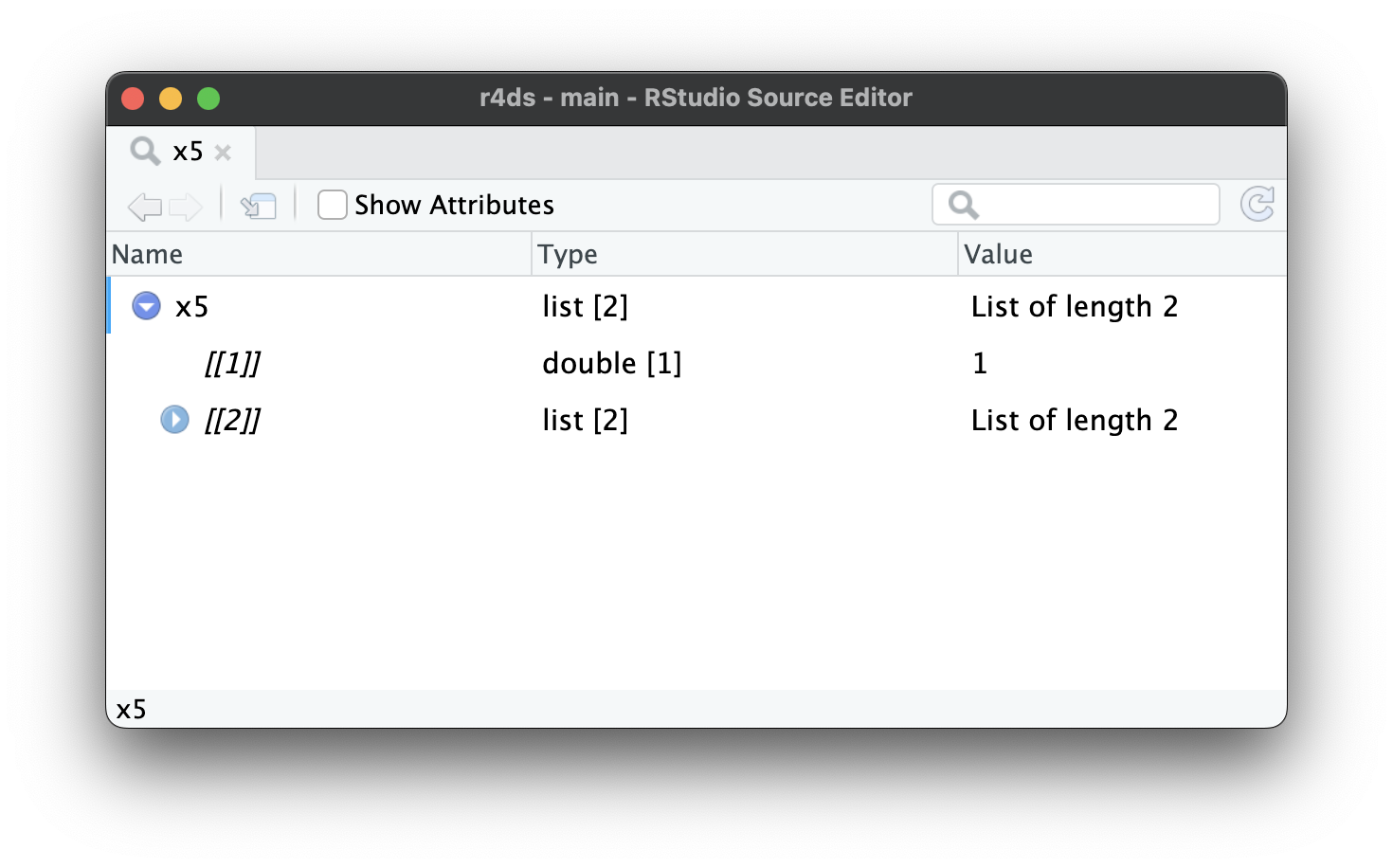
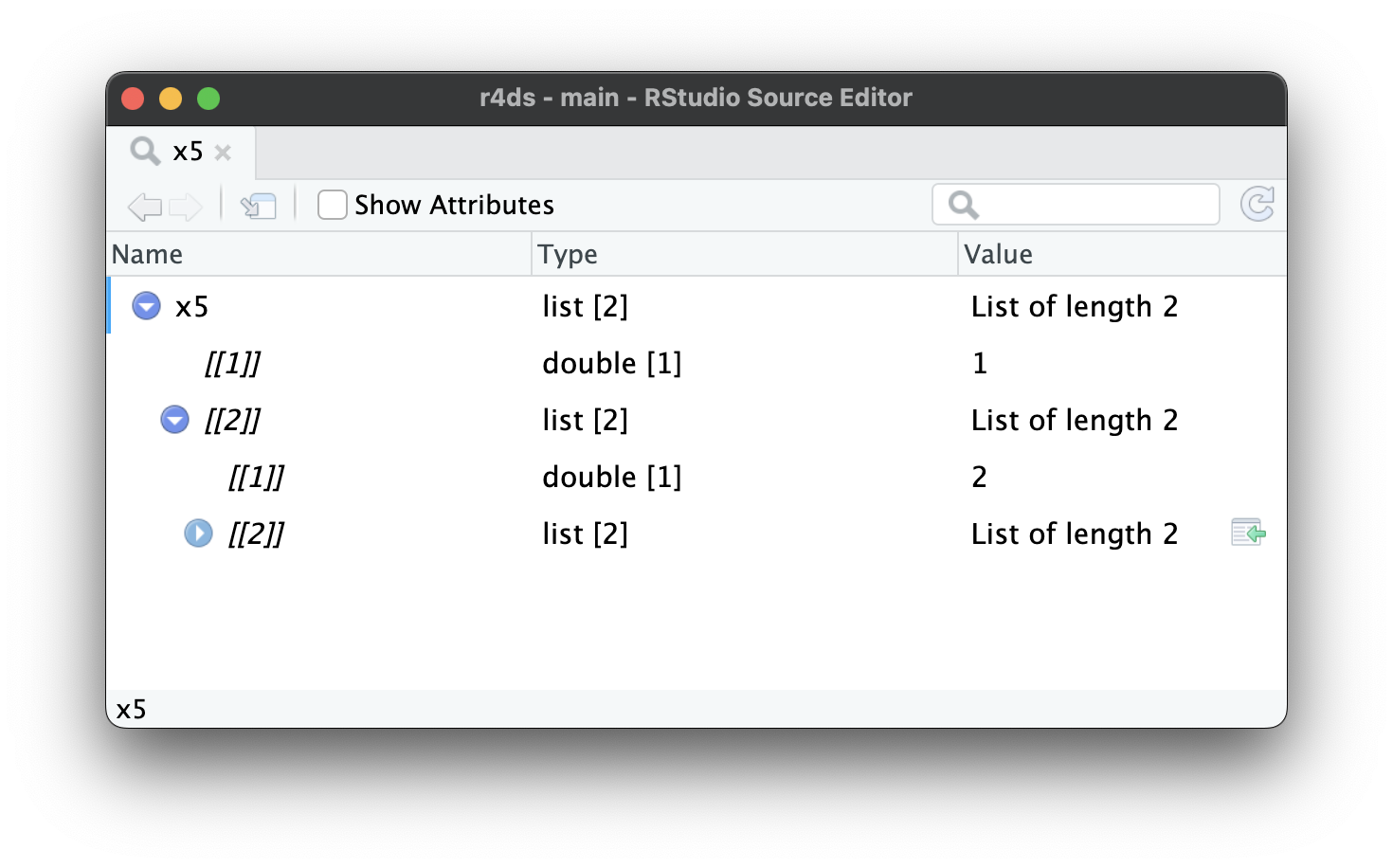
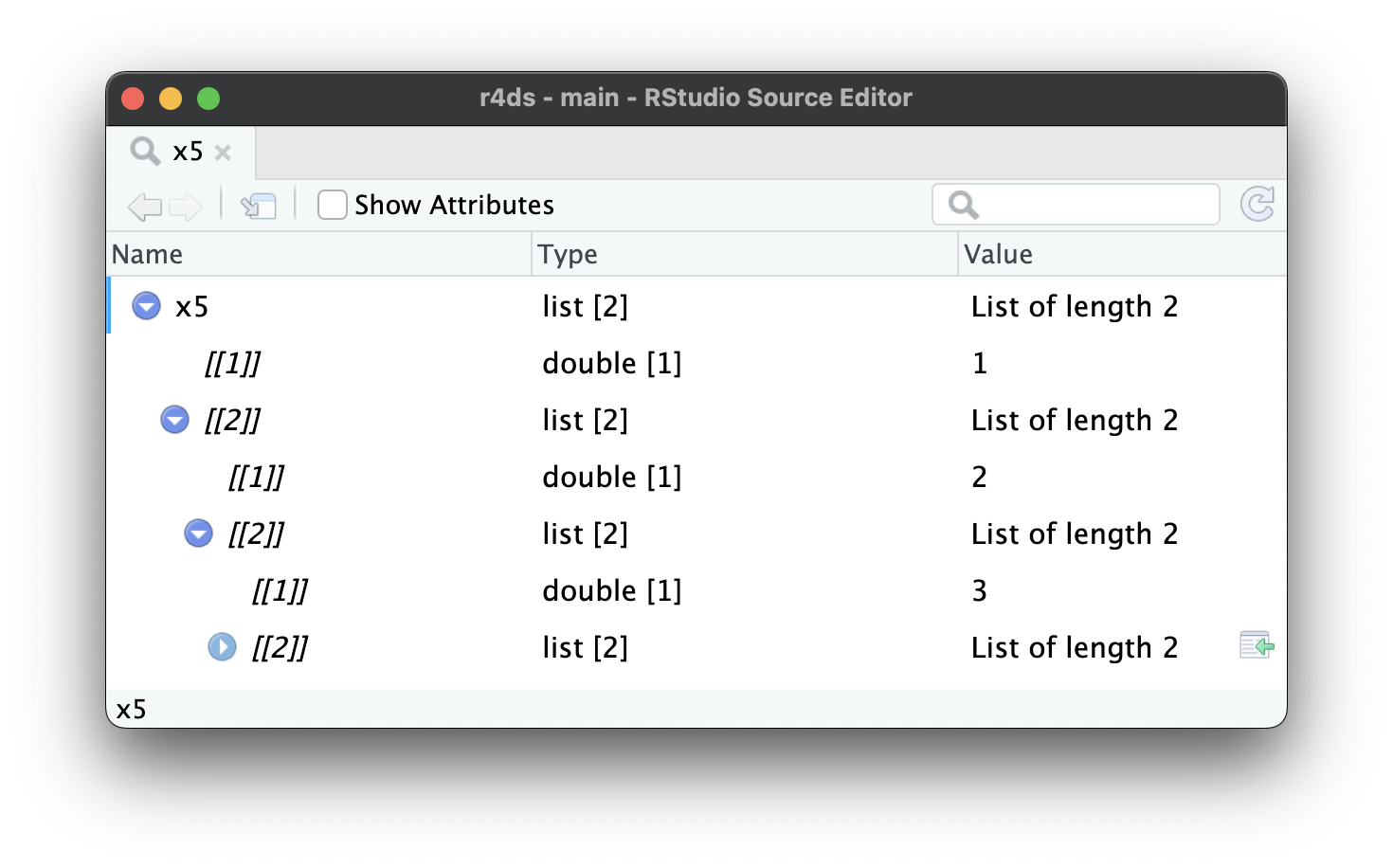
x5[[2]][[2]][[2]].
23.2.2 List-columns
Listas também podem estar presentes em um tibble, quando isto acontece as chamamos de colunas-lista (list-columns). List-columns são úteis porque elas permitem que você coloque objetos em um tibble que normalmente não pertenceriam a ele. Em particular, list-columns são muito usadas no ecosistema tidymodels, pois permitem que você armazene coisas como saída de modelos ou amostras (resamples) em um data frame.
Aqui está um simples exemplo de uma list-column:
Não há nada de especial nesta lista dentro de um tibble; se comportando como qualquer outra coluna:
df |>
filter(x == 1)
#> # A tibble: 1 × 3
#> x y z
#> <int> <chr> <list>
#> 1 1 a <list [2]>Trabalhar com list-column é mais difícil, mas isto se dá porque trabalhar com listas é difícil de modo geral; voltaremos a este assunto no Capítulo 26. Neste capítulo, nos concetraremos em desaninhar (unnest) as colunas-lista em variáveis regulares para que você possa usar tuas ferramentas já existentes nelas.
O método de exibição padrão é um resumo grosseiro de seus conteúdos. A list-column poderia ser arbitrariamente complexa, portanto não há um jeito fácil de exibi-las (“printa-las”). Se quiser visualizá-la, você precisará extrair apenas a list-column em questão e aplicar uma das técnicas que aprendeu acima, como df |> pull(z) |> str() ou df |> pull(z) |> View().
É possível colocar uma lista em uma coluna de um data frame, mas é muito mais complicado, porque data.frame() trata uma lista como uma list-column:
data.frame(x = list(1:3, 3:5))
#> x.1.3 x.3.5
#> 1 1 3
#> 2 2 4
#> 3 3 5Você pode forçar data.frame() a tratar uma lista como uma lista de linhas envolvendo-a com a função I(), mas o resultado não gera uma exibição muito boa:
data.frame(
x = I(list(1:2, 3:5)),
y = c("1, 2", "3, 4, 5")
)
#> x y
#> 1 1, 2 1, 2
#> 2 3, 4, 5 3, 4, 5É mais fácil usar list-columns com tibbles, pois a função tibble() trata listas como vetores e o método de exibição foi projetado tendo listas em mente.
23.3 Desaninhando (unnesting)
Agora que você aprendeu o básico sobre listas e list-columns, vamos explorar como você pode transformá-las novamente em linhas e colunas regulares. Aqui usaremos uma amostra de dados simples para que você entenda a ideia básica; na próxima seção mudaremos para dados reais.
List-columns tendem a aparecer em duas formas básicas: nomeadas (named) e não nomeadas (unnamed). Quando os elementos filhos são nomeados, eles tendem a ter o mesmo nome em todas as linhas. Por exemplo, em df1, cada elemento da list-column y tem dois elementos nomeados a e b. List-columns nomeadas naturalmente se desaninham em colunas: cada elemento nomeado se torna uma nova coluna nomeada.
Quando os elementos filhos são não nomeados, o número de elementos tendem a variar de linha para linha. Por exemplo, em df2, os elementos da list-column y são não nomeados e variam em tamanhos de um até três. List-columns não nomeadas se desaninham naturalmente em linhas: você terá uma linha para cada elemento filho.
tidyr fornece duas funções para estes dois casos: unnest_wider() e unnest_longer(). As seções seguintes explicam como elas funcionam.
23.3.1 unnest_wider()
Quado cada linha tem o mesmo número de elementos com o mesmo nome, como em df1, é natural colocar cada elemento em sua própria coluna com unnest_wider():
df1 |>
unnest_wider(y)
#> # A tibble: 3 × 3
#> x a b
#> <dbl> <dbl> <dbl>
#> 1 1 11 12
#> 2 2 21 22
#> 3 3 31 32Por padrão, os nomes das novas colunas vem exclusivamente dos nomes dos elementos da lista, mas você pode usar o argumento names_sep para solicitar que o nome da coluna seja combinado com o nome do elemento. Isto é útil para remover ambiguidades de nomes repetidos.
df1 |>
unnest_wider(y, names_sep = "_")
#> # A tibble: 3 × 3
#> x y_a y_b
#> <dbl> <dbl> <dbl>
#> 1 1 11 12
#> 2 2 21 22
#> 3 3 31 32
23.3.2 unnest_longer()
Quando cada linha contiver uma lista não nomeada, é mais natural colocar cada elemento em sua própria linha com unnest_longer():
df2 |>
unnest_longer(y)
#> # A tibble: 6 × 2
#> x y
#> <dbl> <dbl>
#> 1 1 11
#> 2 1 12
#> 3 1 13
#> 4 2 21
#> 5 3 31
#> 6 3 32Note como x está duplicado para cada elemento dentro de y: temos uma linha de saída para cada elemento dentro da list-column. Mas o que acontece se algum dos elementos estiver vazio, como no exemplo a seguir?
df6 <- tribble(
~x, ~y,
"a", list(1, 2),
"b", list(3),
"c", list()
)
df6 |> unnest_longer(y)
#> # A tibble: 3 × 2
#> x y
#> <chr> <dbl>
#> 1 a 1
#> 2 a 2
#> 3 b 3Temos zero linhas na saída, portanto a linha efetivamente desaparece. Se quiser preservar esta linha, adicionando NA em y, defina keep_empty = TRUE.
23.3.3 Tipos inconsistentes
O que acontece se você desaninhar uma list-column que contém diferentes tipos de vetores? Por exemplo, veja o seguinte conjunto de dados onde a list-column y contém dois números, um caractere e um lógico, a qual você normalmente não pode juntar em uma única coluna.
unnest_longer() sempre mantém o conjunto de colunas imutável, enquanto muda o número de linhas. Então, o que acontece? Como que unnest_longer() produz cinco linhas e ao mesmo tempo mantém tudo em y?
df4 |>
unnest_longer(y)
#> # A tibble: 4 × 2
#> x y
#> <chr> <list>
#> 1 a <dbl [1]>
#> 2 b <chr [1]>
#> 3 b <lgl [1]>
#> 4 b <dbl [1]>Como você pode ver, a saída contém uma list-column, mas cada elemento da list-column contém um único elemento. Como unnest_longer() não pode encontrar um tipo de vetor comum, ela mantém os tipos originais em uma list-column. Você pode estar se perguntando se isso viola o mandamento de que cada elemento de uma coluna deve ser do mesmo tipo. Não: cada elemento é uma lista, mesmo que os conteúdos sejam de tipos diferentes.
Lidar com tipos inconsistentes é desafiador e os detalhes dependem da natureza precisa do problema e dos seus objetivos, mas você provavelmente precisará de ferramentas do Capítulo 26.
23.3.4 Outras funções
O tidyr tem algumas outras funções de representação retangular que não iremos cobrir neste livro:
-
unnest_auto()automaticamente escolhe entreunnest_longer()eunnest_wider()baseado na estrutura da list-column. Esta função é ótima para uma exploração rápida, mas no fim das contas é uma má ideia pois não força você a entender como seus dados estão estruturados e torna teu código mais difícil de entender. -
unnest()expande tanto linhas quanto colunas. É muito poderosa quando você tem uma list-column que contém uma estrutura 2d como um data frame, algo que você não verá neste livro, mas você deve encontrar se usar o ecosistema tidymodels.
É bom conhecer estas funções pois você pode encontrá-las em códigos de outras pessoas ou enfrentar você mesmo desafios mais raros de representação retangular.
23.3.5 Exercícios
O que acontece quando você utiliza
unnest_wider()com list-columns não nomeadas como emdf2? Qual argumento é necessário agora? O que acontece com valores faltantes (missing)?O que acontece quando você utiliza
unnest_longer()com list-columns nomeadas como emdf1? Qual informação adicional você recebe na saída? Como você pode suprimir estes detalhes extras?-
De tempos em tempos, você encontra data frames com várias list-columns com valores alinhados. Por exemplo, no data frame seguinte, os valores de
yezestão alinhados (ex:yezsempre terão o mesmo tamanho dentro de uma linha e o primeiro valor deycorresponde ao primeiro valor dez). O que acontece quando você executa a funçãounnest_longer()duas vezes neste data frame? Como você pode preservar a relação entrexey? (Dica: leia atentamente a documentação).
23.4 Estudos de casos
A principal diferença entre os exemplos simples que usamos acima e o de dados reais, é que os dados reais tipicamente contém vários níveis de aninhamento (nesting) que requerem o uso consecutivo de unnest_longer() e/ou unnest_wider(). Para mostrar isto em ação, esta seção faz uso de três desafios de representação retangular, usando conjunto de dados do pacote repurrrsive.
23.4.1 Dados bem largos (wide data)
Começaremos com gh_repos. Esta é uma lista que contém dados sobre uma coleção de repositórios do GitHub obtidos usando a API do GitHub. É uma lista aninhada em vários níveis, por isso é difícil de mostrar sua estrutura neste livro; nós recomendamos que você a explore por conta própria usando View(gh_repos) antes de continuar.
gh_repos é uma lista, mas nossas ferramentas trabalham com list-columns, então iremos começar colocando-a em um tibble. Chamaremos esta coluna de json por razões que veremos mais tarde.
repos <- tibble(json = gh_repos)
repos
#> # A tibble: 6 × 1
#> json
#> <list>
#> 1 <list [30]>
#> 2 <list [30]>
#> 3 <list [30]>
#> 4 <list [26]>
#> 5 <list [30]>
#> 6 <list [30]>Este tibble contém 6 linhas, uma linha para cada elemento filho de gh_repos. Cada linha contém uma lista não nomeada com 26 ou 30 linhas. Como elas são não nomeadas, começaremos com unnest_longer() para colocar cada filho em sua própria linha:
repos |>
unnest_longer(json)
#> # A tibble: 176 × 1
#> json
#> <list>
#> 1 <named list [68]>
#> 2 <named list [68]>
#> 3 <named list [68]>
#> 4 <named list [68]>
#> 5 <named list [68]>
#> 6 <named list [68]>
#> # ℹ 170 more rowsÀ primeira vista, pode parecer que não melhoramos a situação: apesar de termos mais linhas (176 ao invés de 6), cada elemento de json ainda é uma lista. Entretando, há uma importante diferença: agora, cada elemento é uma lista nomeada, então podemos usar unnest_wider() para colocar cada elemento em sua própria coluna:
repos |>
unnest_longer(json) |>
unnest_wider(json)
#> # A tibble: 176 × 68
#> id name full_name owner private html_url
#> <int> <chr> <chr> <list> <lgl> <chr>
#> 1 61160198 after gaborcsardi/after <named list> FALSE https://github…
#> 2 40500181 argufy gaborcsardi/argu… <named list> FALSE https://github…
#> 3 36442442 ask gaborcsardi/ask <named list> FALSE https://github…
#> 4 34924886 baseimports gaborcsardi/base… <named list> FALSE https://github…
#> 5 61620661 citest gaborcsardi/cite… <named list> FALSE https://github…
#> 6 33907457 clisymbols gaborcsardi/clis… <named list> FALSE https://github…
#> # ℹ 170 more rows
#> # ℹ 62 more variables: description <chr>, fork <lgl>, url <chr>, …Isto fucionou, mas o resultado ficou um pouco estranho: Existem tantas colunas que o tibble nem exibe todas elas! Podemos ver todas as colunas com names(); e aqui vemos as primeiras 10:
repos |>
unnest_longer(json) |>
unnest_wider(json) |>
names() |>
head(10)
#> [1] "id" "name" "full_name" "owner" "private"
#> [6] "html_url" "description" "fork" "url" "forks_url"Vamos extrair algumas que parecem interessantes:
repos |>
unnest_longer(json) |>
unnest_wider(json) |>
select(id, full_name, owner, description)
#> # A tibble: 176 × 4
#> id full_name owner description
#> <int> <chr> <list> <chr>
#> 1 61160198 gaborcsardi/after <named list [17]> Run Code in the Backgro…
#> 2 40500181 gaborcsardi/argufy <named list [17]> Declarative function ar…
#> 3 36442442 gaborcsardi/ask <named list [17]> Friendly CLI interactio…
#> 4 34924886 gaborcsardi/baseimports <named list [17]> Do we get warnings for …
#> 5 61620661 gaborcsardi/citest <named list [17]> Test R package and repo…
#> 6 33907457 gaborcsardi/clisymbols <named list [17]> Unicode symbols for CLI…
#> # ℹ 170 more rowsVocê pode usar isso para entender como o gh_repos foi estruturado: cada elemento filho era um usuário do GitHub contendo uma lista de até 30 repositórios do GitHub que eles criaram.
owner é uma outra list-column, e uma vez que contém uma lista nomeada, podemos usar unnest_wider() para obter seus valores:
repos |>
unnest_longer(json) |>
unnest_wider(json) |>
select(id, full_name, owner, description) |>
unnest_wider(owner)
#> Error in `unnest_wider()`:
#> ! Can't duplicate names between the affected columns and the original
#> data.
#> ✖ These names are duplicated:
#> ℹ `id`, from `owner`.
#> ℹ Use `names_sep` to disambiguate using the column name.
#> ℹ Or use `names_repair` to specify a repair strategy.Uh uh, esta list-column também contém uma coluna id e não podemos ter duas colunas id no mesmo data frame. Conforme sugerido, vamos usar names_sep para resolver este problema:
repos |>
unnest_longer(json) |>
unnest_wider(json) |>
select(id, full_name, owner, description) |>
unnest_wider(owner, names_sep = "_")
#> # A tibble: 176 × 20
#> id full_name owner_login owner_id owner_avatar_url
#> <int> <chr> <chr> <int> <chr>
#> 1 61160198 gaborcsardi/after gaborcsardi 660288 https://avatars.gith…
#> 2 40500181 gaborcsardi/argufy gaborcsardi 660288 https://avatars.gith…
#> 3 36442442 gaborcsardi/ask gaborcsardi 660288 https://avatars.gith…
#> 4 34924886 gaborcsardi/baseimports gaborcsardi 660288 https://avatars.gith…
#> 5 61620661 gaborcsardi/citest gaborcsardi 660288 https://avatars.gith…
#> 6 33907457 gaborcsardi/clisymbols gaborcsardi 660288 https://avatars.gith…
#> # ℹ 170 more rows
#> # ℹ 15 more variables: owner_gravatar_id <chr>, owner_url <chr>, …Isto nos dá um outro conjunto de dados largo (wide), mas você pode perceber que owner (pessoa proprietária) parece conter muitos dados adicionais sobre a pessoa “proprietária” do repositório.
23.4.2 Dados relacionais
Dados aninhados (nested) muitas vezes são usados para representar dados que normalmente estariam espalhados por vários data frames. Por exemplo, veja got_chars que contém dados sobre os personagens (characters) que aparecem nos livros e série de TV Game of Thrones. Assim como gh_repos, ela também é uma lista, então começamos transformado-a em uma list-column de um tibble:
chars <- tibble(json = got_chars)
chars
#> # A tibble: 30 × 1
#> json
#> <list>
#> 1 <named list [18]>
#> 2 <named list [18]>
#> 3 <named list [18]>
#> 4 <named list [18]>
#> 5 <named list [18]>
#> 6 <named list [18]>
#> # ℹ 24 more rowsA coluna json contém elementos nomeados, estão vamos começar alargando-os (widening):
chars |>
unnest_wider(json)
#> # A tibble: 30 × 18
#> url id name gender culture born
#> <chr> <int> <chr> <chr> <chr> <chr>
#> 1 https://www.anapio… 1022 Theon Greyjoy Male "Ironborn" "In 278 AC or …
#> 2 https://www.anapio… 1052 Tyrion Lannist… Male "" "In 273 AC, at…
#> 3 https://www.anapio… 1074 Victarion Grey… Male "Ironborn" "In 268 AC or …
#> 4 https://www.anapio… 1109 Will Male "" ""
#> 5 https://www.anapio… 1166 Areo Hotah Male "Norvoshi" "In 257 AC or …
#> 6 https://www.anapio… 1267 Chett Male "" "At Hag's Mire"
#> # ℹ 24 more rows
#> # ℹ 12 more variables: died <chr>, alive <lgl>, titles <list>, …E selecionando algumas colunas para lermos mais facilmente:
characters <- chars |>
unnest_wider(json) |>
select(id, name, gender, culture, born, died, alive)
characters
#> # A tibble: 30 × 7
#> id name gender culture born died
#> <int> <chr> <chr> <chr> <chr> <chr>
#> 1 1022 Theon Greyjoy Male "Ironborn" "In 278 AC or 27… ""
#> 2 1052 Tyrion Lannister Male "" "In 273 AC, at C… ""
#> 3 1074 Victarion Greyjoy Male "Ironborn" "In 268 AC or be… ""
#> 4 1109 Will Male "" "" "In 297 AC, at…
#> 5 1166 Areo Hotah Male "Norvoshi" "In 257 AC or be… ""
#> 6 1267 Chett Male "" "At Hag's Mire" "In 299 AC, at…
#> # ℹ 24 more rows
#> # ℹ 1 more variable: alive <lgl>Este conjunto de dados também contém várias list-columns:
chars |>
unnest_wider(json) |>
select(id, where(is.list))
#> # A tibble: 30 × 8
#> id titles aliases allegiances books povBooks tvSeries playedBy
#> <int> <list> <list> <list> <list> <list> <list> <list>
#> 1 1022 <chr [2]> <chr [4]> <chr [1]> <chr [3]> <chr> <chr> <chr>
#> 2 1052 <chr [2]> <chr [11]> <chr [1]> <chr [2]> <chr> <chr> <chr>
#> 3 1074 <chr [2]> <chr [1]> <chr [1]> <chr [3]> <chr> <chr> <chr>
#> 4 1109 <chr [1]> <chr [1]> <NULL> <chr [1]> <chr> <chr> <chr>
#> 5 1166 <chr [1]> <chr [1]> <chr [1]> <chr [3]> <chr> <chr> <chr>
#> 6 1267 <chr [1]> <chr [1]> <NULL> <chr [2]> <chr> <chr> <chr>
#> # ℹ 24 more rowsVamos explorar a coluna titles (títulos). É uma list-column não nomeada, então desaninharemos em linhas:
chars |>
unnest_wider(json) |>
select(id, titles) |>
unnest_longer(titles)
#> # A tibble: 59 × 2
#> id titles
#> <int> <chr>
#> 1 1022 Prince of Winterfell
#> 2 1022 Lord of the Iron Islands (by law of the green lands)
#> 3 1052 Acting Hand of the King (former)
#> 4 1052 Master of Coin (former)
#> 5 1074 Lord Captain of the Iron Fleet
#> 6 1074 Master of the Iron Victory
#> # ℹ 53 more rowsVocê esperaria ver estes dados em um tabela própria, pois seria mais fácil uní-los com os dados dos personagens conforme necessário. Vamos fazer isso, o que requer um pouco de limpeza: removendo as linhas que contém strings vazias e renomeando titles para title já que cada linha agora contém um único título.
titles <- chars |>
unnest_wider(json) |>
select(id, titles) |>
unnest_longer(titles) |>
filter(titles != "") |>
rename(title = titles)
titles
#> # A tibble: 52 × 2
#> id title
#> <int> <chr>
#> 1 1022 Prince of Winterfell
#> 2 1022 Lord of the Iron Islands (by law of the green lands)
#> 3 1052 Acting Hand of the King (former)
#> 4 1052 Master of Coin (former)
#> 5 1074 Lord Captain of the Iron Fleet
#> 6 1074 Master of the Iron Victory
#> # ℹ 46 more rowsVocê poderia imaginar criar uma tabela como esta para cada list-column e então usar uniões (joins) para combiná-las com os dados dos personagens conforme você achar necessário.
23.4.3 Profundamente aninhados (deeply nested)
Concluiremos estes estudos de casos com uma list-column que é profundamente aninhada e requer repetidas rodadas de unnest_wider() e unnest_longer() para ser desvendada: gmaps_cities. Este é um tibble de duas colunas contendo cinco nomes de cidades e o resultado da API de geolocalização do Google para determinar suas localizações:
gmaps_cities
#> # A tibble: 5 × 2
#> city json
#> <chr> <list>
#> 1 Houston <named list [2]>
#> 2 Washington <named list [2]>
#> 3 New York <named list [2]>
#> 4 Chicago <named list [2]>
#> 5 Arlington <named list [2]>json é uma list-column nomeada, portanto iremos começar com unnest_wider():
gmaps_cities |>
unnest_wider(json)
#> # A tibble: 5 × 3
#> city results status
#> <chr> <list> <chr>
#> 1 Houston <list [1]> OK
#> 2 Washington <list [2]> OK
#> 3 New York <list [1]> OK
#> 4 Chicago <list [1]> OK
#> 5 Arlington <list [2]> OKIsto nos retorna status e results. Iremos remover a coluna status já que são todos OK; em uma análise real, você também iria capturar todas as linhas onde status != "OK" e entender o que deu errado. results é uma lista não nomeada, com um ou dois elementos (veremos porque em breve), portanto iremos desaninhá-la em linhas:
gmaps_cities |>
unnest_wider(json) |>
select(-status) |>
unnest_longer(results)
#> # A tibble: 7 × 2
#> city results
#> <chr> <list>
#> 1 Houston <named list [5]>
#> 2 Washington <named list [5]>
#> 3 Washington <named list [5]>
#> 4 New York <named list [5]>
#> 5 Chicago <named list [5]>
#> 6 Arlington <named list [5]>
#> # ℹ 1 more rowAgora results é uma lista nomeada, então usaremos unnest_wider():
locations <- gmaps_cities |>
unnest_wider(json) |>
select(-status) |>
unnest_longer(results) |>
unnest_wider(results)
locations
#> # A tibble: 7 × 6
#> city address_components formatted_address geometry
#> <chr> <list> <chr> <list>
#> 1 Houston <list [4]> Houston, TX, USA <named list [4]>
#> 2 Washington <list [2]> Washington, USA <named list [4]>
#> 3 Washington <list [4]> Washington, DC, USA <named list [4]>
#> 4 New York <list [3]> New York, NY, USA <named list [4]>
#> 5 Chicago <list [4]> Chicago, IL, USA <named list [4]>
#> 6 Arlington <list [4]> Arlington, TX, USA <named list [4]>
#> # ℹ 1 more row
#> # ℹ 2 more variables: place_id <chr>, types <list>Agora podemos ver porque duas cidades tinham dois resultados: Washington correspondeu ao estado Washington e Washington, DC e Arlington correspondeu a Arlington, Virginia e Arlington, Texas.
Há vários lugares que podemos ir a partir daqui. Poderíamos querer determinar a localização exata da localidade correspondente, a qual é armazenada na list-column geometry:
locations |>
select(city, formatted_address, geometry) |>
unnest_wider(geometry)
#> # A tibble: 7 × 6
#> city formatted_address bounds location location_type
#> <chr> <chr> <list> <list> <chr>
#> 1 Houston Houston, TX, USA <named list [2]> <named list> APPROXIMATE
#> 2 Washington Washington, USA <named list [2]> <named list> APPROXIMATE
#> 3 Washington Washington, DC, USA <named list [2]> <named list> APPROXIMATE
#> 4 New York New York, NY, USA <named list [2]> <named list> APPROXIMATE
#> 5 Chicago Chicago, IL, USA <named list [2]> <named list> APPROXIMATE
#> 6 Arlington Arlington, TX, USA <named list [2]> <named list> APPROXIMATE
#> # ℹ 1 more row
#> # ℹ 1 more variable: viewport <list>Isto nos dá novos bounds (uma região retangular) e location (um ponto). Podemos desaninhar location para vermos a latitude (lat) e longitude (lng):
locations |>
select(city, formatted_address, geometry) |>
unnest_wider(geometry) |>
unnest_wider(location)
#> # A tibble: 7 × 7
#> city formatted_address bounds lat lng location_type
#> <chr> <chr> <list> <dbl> <dbl> <chr>
#> 1 Houston Houston, TX, USA <named list [2]> 29.8 -95.4 APPROXIMATE
#> 2 Washington Washington, USA <named list [2]> 47.8 -121. APPROXIMATE
#> 3 Washington Washington, DC, USA <named list [2]> 38.9 -77.0 APPROXIMATE
#> 4 New York New York, NY, USA <named list [2]> 40.7 -74.0 APPROXIMATE
#> 5 Chicago Chicago, IL, USA <named list [2]> 41.9 -87.6 APPROXIMATE
#> 6 Arlington Arlington, TX, USA <named list [2]> 32.7 -97.1 APPROXIMATE
#> # ℹ 1 more row
#> # ℹ 1 more variable: viewport <list>Alguns passos adicionais são necessários para extrairmos os bounds:
locations |>
select(city, formatted_address, geometry) |>
unnest_wider(geometry) |>
# foco na variável de interesse
select(!location:viewport) |>
unnest_wider(bounds)
#> # A tibble: 7 × 4
#> city formatted_address northeast southwest
#> <chr> <chr> <list> <list>
#> 1 Houston Houston, TX, USA <named list [2]> <named list [2]>
#> 2 Washington Washington, USA <named list [2]> <named list [2]>
#> 3 Washington Washington, DC, USA <named list [2]> <named list [2]>
#> 4 New York New York, NY, USA <named list [2]> <named list [2]>
#> 5 Chicago Chicago, IL, USA <named list [2]> <named list [2]>
#> 6 Arlington Arlington, TX, USA <named list [2]> <named list [2]>
#> # ℹ 1 more rowEntão renomeamos southwest e northeast (os cantos do retângulo) para podermos usar names_sep para criar nomes curtos porém com algum significado:
locations |>
select(city, formatted_address, geometry) |>
unnest_wider(geometry) |>
select(!location:viewport) |>
unnest_wider(bounds) |>
rename(ne = northeast, sw = southwest) |>
unnest_wider(c(ne, sw), names_sep = "_")
#> # A tibble: 7 × 6
#> city formatted_address ne_lat ne_lng sw_lat sw_lng
#> <chr> <chr> <dbl> <dbl> <dbl> <dbl>
#> 1 Houston Houston, TX, USA 30.1 -95.0 29.5 -95.8
#> 2 Washington Washington, USA 49.0 -117. 45.5 -125.
#> 3 Washington Washington, DC, USA 39.0 -76.9 38.8 -77.1
#> 4 New York New York, NY, USA 40.9 -73.7 40.5 -74.3
#> 5 Chicago Chicago, IL, USA 42.0 -87.5 41.6 -87.9
#> 6 Arlington Arlington, TX, USA 32.8 -97.0 32.6 -97.2
#> # ℹ 1 more rowVeja como desaninhamos duas colunas simultaneamente fornecendo um vetor com os nomes das variáveis para unnest_wider().
Uma vez que você descobriu o caminho para os elementos de interesse, você pode extraí-los diretamente usando outra função tidyr, hoist():
Se esses estudos de caso aguçaram seu apetite para mais representações retangulares na vida real, você pode ver alguns outros exemplos na vignette("rectangling", package = "tidyr").
23.4.4 Exercícios
Estime aproximadamente quando o
gh_reposfoi criado. Porque você só pode estimar aproximadamente esta data?A coluna
ownerdogh_repocontém muitas informações duplicadas pois cada pessoa proprietária pode ter vários repositórios. Você consegue contruir um data frameownersque contém uma linha para cada pessoa proprietária? (Dica: Adistinct()funciona comlist-cols?)Siga os passos usados em
titlespara criar tabelas similares para aliases, allegiances, books e TV Series para os personagens de Game of Thrones.-
Explique o seguinte código linha a linha. Por que este código é interessante? Por que ele funciona para
got_charsmas pode não funcionar em geral?tibble(json = got_chars) |> unnest_wider(json) |> select(id, where(is.list)) |> pivot_longer( where(is.list), names_to = "name", values_to = "value" ) |> unnest_longer(value) No
gmaps_cities, o queaddress_componentscontém? Por que o tamanho varia entre as linhas? Desaninhe-o devidamente para entender. (Dica:typesparece ter sempre dois elementos. Ounnest_wider()funcionaria mais fácil que ounnest_longer()?) .
23.5 JSON
Todos os estudos de caso na seção anterior foram originados de JSONs bruto/proveniente de fontes diretas. JSON é abreviação de javascript object notation e é a forma que a maioria das APIs da web retornam dados. É importante saber que apesar dos tipos de dados JSON e R serem muito similares, não há uma correspondência de mapeamento 1-para-1, portanto é bom entender um pouco sobre JSON caso algo dê errado.
23.5.1 Tipos de dados
JSON é um formato simples projetado para ser lido e escrito por máquinas, não humanos. Ele tem seis tipos de dados chaves. Quatro deles são escalares:
- O tipo mais simples é o nulo (
null) que tem o mesmo papel doNAno R. Representa ausência de dados. - string é muito parecido com string no R, porém deve ter sempre aspas duplas.
-
number é similar o number do R: podem ser inteiro (e.x., 123), decimal (e.x., 123.45), or notação científica (e.x., 1.23e3). JSON não suporta
Inf,-Inf, ouNaN. -
boolean é similar a
TRUEeFALSEdo R, mas usa letras minúsculastrueefalse.
Strings, números e booleanos do JSON são muito similares aos vetores de caracteres, numéricos e lógicos do R. A principal diferença é que os escalares do JSON podem representar apenas um único valor. Para representar valores múltiplos você precisa usar algum dos outros dois tipos: arrays e objects.
Tanto arrays quanto objects são similares às listas no R; a diferença é se são nomeados ou não nomeados. Um array é como uma lista não nomeada e é escrito com []. Por exemplo, [1, 2, 3] é um array contendo 3 números e [null, 1, "string", false] é um array que contém um nulo, um número, uma string e um booleano. Um object é como uma lista nomeada e é escrito com {}. Os nomes (chaves na terminologia JSON) são strings, portanto devem ter aspas. Por exemplo, {"x": 1, "y": 2} é um objeto que mapeia 1 para x e 2 para y.
Note que JSON não possui um jeito nativo para representar datas e data_hora (datetime), então estes são geralmente armazenados como strings e você deverá usar readr::parse_date() ou readr::parse_datetime() para transformá-los na estrutura de dados correta. Da mesma forma, a regras do JSON para representar número com ponto flutuante (floating points), são um pouco imprecisas, portanto você também encontrará algumas vezes números armazenados como strings. Aplique readr::parse_double() conforme necessário para obter os tipo correto.
23.5.2 jsonlite
Para converter JSON em estruturas de dados do R, recomendamos o pacote jsonlite, de Jeroen Ooms. Usaremos apenas duas funções do jsonlite: read_json() e parse_json(). Na vida real, você usará read_json() para importar arquivos JSON do disco. Por exemplo, o pacote repurrsive também é a fonte do gh_user como um arquivo JSON e você pode importá-la com read_json():
# Um caminho para o arquivo JSON dentro do pacote:
gh_users_json()
#> [1] "/Library/Frameworks/R.framework/Versions/4.4-arm64/Resources/library/repurrrsive/extdata/gh_users.json"
# Importe com read_json()
gh_users2 <- read_json(gh_users_json())
# Verifique se é o mesmo dado que usamos anteriormente
identical(gh_users, gh_users2)
#> [1] TRUENeste livro, usaremos também parse_json(), que recebe uma string representando um JSON, o que a torna boa para gerar exemplos simples. Para começar, aqui estão três simples conjuntos de dados JSON, começando com um número, e então adicionando alguns números em array e em seguida adicionando esse array em um object:
str(parse_json('1'))
#> int 1
str(parse_json('[1, 2, 3]'))
#> List of 3
#> $ : int 1
#> $ : int 2
#> $ : int 3
str(parse_json('{"x": [1, 2, 3]}'))
#> List of 1
#> $ x:List of 3
#> ..$ : int 1
#> ..$ : int 2
#> ..$ : int 3jsonlite tem uma outra função importante chamada fromJSON(). Não a usamos aqui, pois efetua uma simplificação automática (simplifyVector = TRUE). Isto geralmente funciona bem, particularmente em casos simples, mas achamos que é mais vantajoso se fizer você mesmo a representação retangular para que saiba exatamente o que está acontecendo e possa lidar mais facilmente com estruturas aninhadas mais complexas.
23.5.3 Iniciando o processo de representação retangular
Na maioria dos casos, arquivos JSON contém um único array de nível mais alto (top-level), pois são projetados para prover dados sobre várias “coisas”, e.x. várias páginas, ou vários registros, ou vários resultados. Neste caso, você comecará sua representação retangular com tibble(json) para que cada elemento se torne uma linha:
json <- '[
{"nome": "John", "idade": 34},
{"nome": "Susan", "idade": 27}
]'
df <- tibble(json = parse_json(json))
df
#> # A tibble: 2 × 1
#> json
#> <list>
#> 1 <named list [2]>
#> 2 <named list [2]>
df |>
unnest_wider(json)
#> # A tibble: 2 × 2
#> nome idade
#> <chr> <int>
#> 1 John 34
#> 2 Susan 27Em alguns casos raros, arquivos JSON são constituídos por um único object no nível mais alto, representando uma “coisa”. Neste caso, você precisará iniciar o processo de representação retangular colocando-o em uma lista antes de colocá-lo em um tibble.
json <- '{
"status": "OK",
"results": [
{"nome": "John", "idade": 34},
{"nome": "Susan", "idade": 27}
]
}
'
df <- tibble(json = list(parse_json(json)))
df
#> # A tibble: 1 × 1
#> json
#> <list>
#> 1 <named list [2]>
df |>
unnest_wider(json) |>
unnest_longer(results) |>
unnest_wider(results)
#> # A tibble: 2 × 3
#> status nome idade
#> <chr> <chr> <int>
#> 1 OK John 34
#> 2 OK Susan 27Alternativamente, você pode acessar o JSON analisado e começar com a parte que realmente lhe interessa:
df <- tibble(results = parse_json(json)$results)
df |>
unnest_wider(results)
#> # A tibble: 2 × 2
#> nome idade
#> <chr> <int>
#> 1 John 34
#> 2 Susan 2723.5.4 Exercícios
-
Represente retangularmente o
df_coledf_linhaabaixo. Eles representam duas formas de codificar um data frame em JSON.json_col <- parse_json(' { "x": ["a", "x", "z"], "y": [10, null, 3] } ') json_linha <- parse_json(' [ {"x": "a", "y": 10}, {"x": "x", "y": null}, {"x": "z", "y": 3} ] ') df_col <- tibble(json = list(json_col)) df_linha <- tibble(json = json_linha)
23.6 Resumo
Neste capítulo, você aprendeu o que são listas, como você pode gerá-las a partir de arquivos JSON e como transformá-las em data frames retangulares. Surpreendentemente, precisamos de apenas duas funções: unnest_longer() para colocar elementos da lista em linhas e unnest_wider() para colocar os elementos da lista em colunas. Não importa quão profundamente aninhada esteja a list-column; tudo que você precisa fazer é chamar repetidamente essas duas funções.
JSON é o formato de dados mais comum retornados por APIs web. E se o website não possuir uma API, mas você puder ver os dados desejados no website? Este é o tópico do próximo capítulo: Raspagem de dados (web scraping), extraindo dados de páginas web HTML.
Esta é uma funcionalidade do RStudio.↩︎